Modelos de Probabilidad
Se trata de modelos del tipo:
Veamos un ejemplo: Abrir la base MROZ de Wooldridge y ajuste el modelo:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# np.set_printoptions(precision=2)
uu = "https://raw.githubusercontent.com/vmoprojs/DataLectures/master/WO/mroz.csv"
datos = pd.read_csv(uu,header = None)
datos.columns = ["inlf","hours", "kidslt6", "kidsge6",
"age", "educ", "wage",
"repwage","hushrs" , "husage", "huseduc" ,
"huswage" , "faminc", "mtr","motheduc",
"fatheduc" , "unem", "city" , "exper" ,
"nwifeinc" , "lwage" ,"expersq"]
import statsmodels.formula.api as stm
from statsmodels.graphics.regressionplots import abline_plot
from scipy import stats
reg1 = stm.ols('inlf ~ nwifeinc + educ + exper + expersq + age+kidslt6 + kidsge6',data = datos).fit()
print(reg1.summary()) OLS Regression Results
==============================================================================
Dep. Variable: inlf R-squared: 0.264
Model: OLS Adj. R-squared: 0.257
Method: Least Squares F-statistic: 38.22
Date: Tue, 28 Mar 2023 Prob (F-statistic): 6.90e-46
Time: 03:58:25 Log-Likelihood: -423.89
No. Observations: 753 AIC: 863.8
Df Residuals: 745 BIC: 900.8
Df Model: 7
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.5855 0.154 3.798 0.000 0.283 0.888
nwifeinc -0.0034 0.001 -2.351 0.019 -0.006 -0.001
educ 0.0380 0.007 5.151 0.000 0.024 0.052
exper 0.0395 0.006 6.962 0.000 0.028 0.051
expersq -0.0006 0.000 -3.227 0.001 -0.001 -0.000
age -0.0161 0.002 -6.476 0.000 -0.021 -0.011
kidslt6 -0.2618 0.034 -7.814 0.000 -0.328 -0.196
kidsge6 0.0130 0.013 0.986 0.324 -0.013 0.039
==============================================================================
Omnibus: 169.137 Durbin-Watson: 0.494
Prob(Omnibus): 0.000 Jarque-Bera (JB): 36.741
Skew: -0.196 Prob(JB): 1.05e-08
Kurtosis: 1.991 Cond. No. 3.06e+03
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 3.06e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
¿Qué hemos ajustado?
aux = stm.ols('inlf ~ educ',data = datos).fit()
plt.figure()
plt.plot(datos.educ,datos.inlf,'o');
plt.plot(datos.educ,aux.fittedvalues,'-',color='r');
plt.xlabel('educ');
plt.ylabel('inlf');
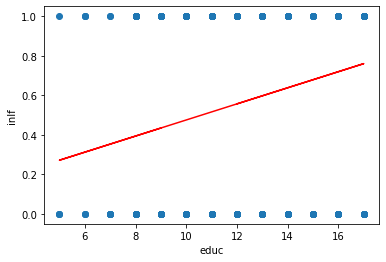
Excepto kidsge6 los coeficientes son significativos.
Se introdujo la experiencia cuadrática para capturar un efecto decreciente en el efecto deseado (
inlf). ¿Cómo lo interpretamos?
.039 - 2(.0006)exper = 0.39 - .0012exper
El punto en el que la experiencia ya no tiene efecto en
inlfes . ¿Cuantos elementos de la muestra tienen más de 32 años de experiencia?
Se añade exper al cuadrado porque queremos dar la posibilidad que los años adicionales de expericnecia contribuyan con un efecto decreciente.
Trabajemos ahora con la predicción, y revisemos el resultado:
pred_vals = reg1.predict()
aux = list(zip(datos.inlf,pred_vals))
print(aux[0:5])
stats.describe(pred_vals)[(1, 0.6636123221355531), (1, 0.7009165727274161), (1, 0.6727286212890489), (1, 0.7257441305286613), (1, 0.5616358247349608)]
DescribeResult(nobs=753, minmax=(-0.34511026465740724, 1.1271505290421115), mean=0.5683930942895072, variance=0.06490433214015544, skewness=-0.4241251818053419, kurtosis=-0.07391834122184537)¿Qué podemos notar?
Existen valores mayores a 1 e inferiores a 0.
ya no es interpretable en estas regresiones.
Usaremos una probabilidad de ocurrencia, digamos 0.5
prediccion_dum = (pred_vals>=0.5)*1
tab = pd.crosstab(datos.inlf,prediccion_dum)
(tab.iloc[0,0]+tab.iloc[1,1])/datos.shape[0]0.7343957503320053Logit¶
La regresión logística puede entenderse simplemente como encontrar los parámtros que mejor asjuten:
Donde se asume que el error tiene una distribución logística estándar
Donde es el parámetro de escala y el de locación (sech es la función secante hiperbólico).
Otra forma de entender la regresión logística es a través de la función logística:
donde y .
Asumiento como una función lineal de una variable explicativa , tenemos:
Ahora la función logística se puede expresar:
Ten en cuenta que se interpreta como la probabilidad de que la variable dependiente iguale a éxito en lugar de un fracaso. Está claro que las variables de respuesta no se distribuyen de forma idéntica: difiere de un punto a otro, aunque son independientes dado que la matriz de diseño y los parámetros compartidos .
Finalmente definimos la inversa de la función logística, , el logit (log odds):
lo que es equivalente a:
Interpretación:
es la función logit. La ecuación para ilustra que el logit (es decir, log-odds o logaritmo natural de las probabilidades) es equivalente a la expresión de regresión lineal.
denota el logaritmo natural.
es la probabilidad de que la variable dependiente sea igual a un caso, dada alguna combinación lineal de los predictores. La fórmula para ilustra que la probabilidad de que la variable dependiente iguale un caso es igual al valor de la función logística de la expresión de regresión lineal. Esto es importante porque muestra que el valor de la expresión de regresión lineal puede variar de infinito negativo a positivo y, sin embargo, después de la transformación, la expresión resultante para la probabilidad oscila entre 0 y 1.
es la intersección de la ecuación de regresión lineal (el valor del criterio cuando el predictor es igual a cero).
es el coeficiente de regresión multiplicado por algún valor del predictor.
la base denota la función exponencial.
Ejemplo
Abra la tabla 15.7
Los datos son el efecto del Sistema de Enseñanza Personalizada (PSI) sobre las calificaciones.
Calificación si la calificación final fue A
si la calificación final fue B o C
TUCE= calificación en un examen presentado al comienzo del curso para evaluar los conocimientos previos de macroeconomíaPSI= 1 con el nuevo método de enseñanza, 0 en otro casoGPA= promedio de puntos de calificación inicial
Ajuste el siguiente modelo:
ajuste1 <- glm(GRADE~GPA+TUCE+PSI, family=binomial(link="logit"),x=T)Interprete el modelo
En los modelos cuya variable regresada binaria, la bondad del ajuste tiene una importancia secundaria. Lo que interesa son los signos esperados de los coeficientes de la regresión y su importancia práctica y/o estadística.
Importamos los datos y revisamos la variable dependiente:
uu = "https://raw.githubusercontent.com/vmoprojs/DataLectures/master/GA/tabla15_7.csv"
datos = pd.read_csv(uu,sep = ';')
datos.columns
# import statsmodels.api as sm
datos.pivot_table(index = 'GRADE', aggfunc = [len])Ajustamos el modelo:
ajuste1 = stm.logit('GRADE ~ GPA + TUCE + PSI',data = datos).fit()
print(ajuste1.summary())Optimization terminated successfully.
Current function value: 0.402801
Iterations 7
Logit Regression Results
==============================================================================
Dep. Variable: GRADE No. Observations: 32
Model: Logit Df Residuals: 28
Method: MLE Df Model: 3
Date: Tue, 28 Mar 2023 Pseudo R-squ.: 0.3740
Time: 04:00:30 Log-Likelihood: -12.890
converged: True LL-Null: -20.592
Covariance Type: nonrobust LLR p-value: 0.001502
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -13.0213 4.931 -2.641 0.008 -22.687 -3.356
GPA 2.8261 1.263 2.238 0.025 0.351 5.301
TUCE 0.0952 0.142 0.672 0.501 -0.182 0.373
PSI 2.3787 1.065 2.234 0.025 0.292 4.465
==============================================================================
ajuste1.get_margeff(at='mean').summary()mm = ajuste1.get_margeff(at='all').margeff
mm[0:10,:]array([[0.07311607, 0.00246188, 0.06154047],
[0.15815168, 0.0053251 , 0.1331134 ],
[0.43011639, 0.01448239, 0.36202116],
[0.07130492, 0.0024009 , 0.06001605],
[0.69272252, 0.02332457, 0.58305197],
[0.09507939, 0.00320141, 0.08002659],
[0.0729182 , 0.00245522, 0.06137393],
[0.1381988 , 0.00465327, 0.11631942],
[0.2791564 , 0.00939944, 0.23496087],
[0.60069976, 0.02022608, 0.50559808]])¿Son, en conjunto, los coeficientes significativos?
hyp = '(Intercept = 0, GPA = 0,TUCE=0,PSI=0)'
ajuste1.wald_test(hyp,scalar = True)<class 'statsmodels.stats.contrast.ContrastResults'>
<Wald test (chi2): statistic=8.873128862019582, p-value=0.06435007959304277, df_denom=4>np.exp(ajuste1.params)Intercept 0.000002
GPA 16.879715
TUCE 1.099832
PSI 10.790732
dtype: float64Esto indica que los estudiantes expuestos al nuevo método de enseñanza son 10 veces más propensos a obtener una A que quienes no están expuestos al nuevo método, en tanto no cambien los demás factores.
ajuste1.predict(linear = False)array([0.02657799, 0.05950125, 0.18725993, 0.02590164, 0.56989295,
0.03485827, 0.02650406, 0.051559 , 0.11112666, 0.69351131,
0.02447037, 0.18999744, 0.32223955, 0.19321116, 0.36098992,
0.03018375, 0.05362641, 0.03858834, 0.58987249, 0.66078584,
0.06137585, 0.90484727, 0.24177245, 0.85209089, 0.83829051,
0.48113304, 0.63542059, 0.30721866, 0.84170413, 0.94534025,
0.5291172 , 0.11103084])Probit¶
En los modelos logia se propuso la logística, en este caso se propone la Función de Distribución Acumulada Normal. Suponga que la variable de respuesta es binaria, 1 o 0. podría representar la presencia/ausencia de una condición, éxito/fracaso, si/no. Se tiene también un vector de regresoras , el modelo toma la forma:
donde es la prbabilidad y distribución acumulada de la normal estándar . Los parámetros se estiman típicamente con el método de máxima verosimilitud.
Ejemplo
ajuste1 = stm.probit('GRADE ~ GPA + TUCE + PSI',data = datos).fit()
print(ajuste1.summary())Optimization terminated successfully.
Current function value: 0.400588
Iterations 6
Probit Regression Results
==============================================================================
Dep. Variable: GRADE No. Observations: 32
Model: Probit Df Residuals: 28
Method: MLE Df Model: 3
Date: Tue, 28 Mar 2023 Pseudo R-squ.: 0.3775
Time: 04:02:11 Log-Likelihood: -12.819
converged: True LL-Null: -20.592
Covariance Type: nonrobust LLR p-value: 0.001405
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -7.4523 2.542 -2.931 0.003 -12.435 -2.469
GPA 1.6258 0.694 2.343 0.019 0.266 2.986
TUCE 0.0517 0.084 0.617 0.537 -0.113 0.216
PSI 1.4263 0.595 2.397 0.017 0.260 2.593
==============================================================================
ajuste1.get_margeff(at='mean').summary()mm = ajuste1.get_margeff(at='all').margeff
mm[0:10,:]array([[0.07255307, 0.00230845, 0.06365122],
[0.17584323, 0.00559486, 0.15426826],
[0.44108314, 0.01403409, 0.38696473],
[0.07391114, 0.00235166, 0.06484266],
[0.64252589, 0.02044346, 0.5636916 ],
[0.10206861, 0.00324755, 0.08954537],
[0.07368267, 0.00234439, 0.06464222],
[0.15292232, 0.00486558, 0.13415961],
[0.3033272 , 0.00965106, 0.26611067],
[0.59359928, 0.01888675, 0.520768 ]])ajuste1.predict(linear = False)array([0.01817074, 0.05308048, 0.18992627, 0.01857067, 0.55457485,
0.02723306, 0.01850327, 0.04457139, 0.10880811, 0.66312068,
0.01610236, 0.19355656, 0.32332821, 0.19518259, 0.35634057,
0.02196542, 0.04569425, 0.03085127, 0.59340229, 0.65718629,
0.06192878, 0.90453884, 0.2731908 , 0.84745013, 0.83419472,
0.48872605, 0.64240727, 0.3286732 , 0.84001686, 0.95224465,
0.53995949, 0.123544 ])