5. Pruebas de Hipótesis#
En toda prueba de hipótesis, implícita o explícitamente se cubren los siguientes puntos:
5.1. 1. Planteamiento de las hipótesis#
Hipótesis nula (\( H_0 \)): Afirmación que se quiere poner a prueba; generalmente representa la ausencia de efecto, diferencia o relación.
Hipótesis alternativa (\( H_1 \) o \( H_a \)): Afirmación que se aceptaría si se rechaza \( H_0 \); representa la existencia de un efecto, diferencia o relación.
5.2. 2. Elección del nivel de significancia (\( \alpha \))#
Es la probabilidad máxima de cometer un error tipo I (rechazar \( H_0 \) cuando es verdadera).
Comúnmente se usa \( \alpha = 0.05 \), aunque puede variar según el contexto (por ejemplo, \( \alpha = 0.01 \) en estudios médicos).
5.3. 3. Selección del estadístico de prueba#
Depende del tipo de variable y del contraste planteado:
\( t \)-student para medias (cuando la varianza poblacional es desconocida).
\( z \) para proporciones o medias (cuando la varianza es conocida).
\( \chi^2 \) para variables categóricas (pruebas de independencia o bondad de ajuste).
\( F \) para comparar varianzas o modelos (ANOVA, regresión).
5.4. 4. Distribución del estadístico bajo \( H_0 \)#
Determina cómo se comporta el estadístico si la hipótesis nula es verdadera.
Se utiliza para obtener el valor crítico o el p-valor.
5.5. 5. Criterio de decisión#
Valor crítico: Se compara el estadístico con un umbral derivado de la distribución teórica.
P-valor: Probabilidad de obtener un resultado tan extremo como el observado, bajo \( H_0 \).
Si \( \text{p-valor} < \alpha \), se rechaza \( H_0 \).
Si \( \text{p-valor} \geq \alpha \), no se rechaza \(H_0 \).
5.6. 6. Conclusión#
La conclusión debe estar formulada en el contexto del problema.
Nunca se dice que \( H_0 \) es “verdadera”, sino que no hay suficiente evidencia para rechazarla.
5.7. 7. Errores posibles#
Error tipo I (\( \alpha \)): Rechazar \( H_0 \) siendo verdadera.
Error tipo II (\( \beta \)): No rechazar \( H_0 \) siendo falsa.
Poder de la prueba: \( 1 - \beta \), probabilidad de detectar un efecto si realmente existe.
Matriz de confusión adaptada a pruebas de hipótesis
Realidad: \( H_0 \) verdadera |
Realidad: \( H_0 \) falsa |
|
|---|---|---|
Decisión: No rechazar \( H_0 \) |
Verdadero negativo (decisión correcta) |
Error tipo II (falso negativo) |
Decisión: Rechazar \( H_0 \) |
Error tipo I (falso positivo) |
Verdadero positivo (decisión correcta) |
Interpretación de cada celda
Término |
Significado |
|---|---|
Error tipo I |
Rechazar \( H_0 \) cuando en realidad es cierta. |
Error tipo II |
No rechazar \( H_0 \) cuando en realidad es falsa. |
Verdadero negativo |
Decidir no rechazar \( H_0 \) y que efectivamente \(H_0 \) sea verdadera. |
Verdadero positivo |
Rechazar \( H_0 \) y que efectivamente \( H_0 \) sea falsa. |
Probabilidades asociadas
Concepto |
Símbolo |
Definición |
|---|---|---|
Nivel de significancia |
\( \alpha \) |
Probabilidad de cometer un error tipo I. |
Poder de la prueba |
\(1 - \beta \) |
Probabilidad de rechazar \( H_0 \) cuando \( H_0 \) es falsa (acierto). |
Error tipo II |
\( \beta \) |
Probabilidad de no rechazar \(H_0 \) cuando es falsa. |
Conexión con la matriz de confusión en clasificación
Realidad / Predicción |
Clase negativa (0) |
Clase positiva (1) |
|---|---|---|
Verdadero negativo |
Predijo 0, era 0 |
|
Falso positivo |
Predijo 1, era 0 |
(Error tipo I) |
Falso negativo |
Predijo 0, era 1 |
(Error tipo II) |
Verdadero positivo |
Predijo 1, era 1 |
En pruebas de hipótesis:
La “predicción” corresponde a la decisión estadística (rechazar o no rechazar \( H_0 \)).
La “realidad” corresponde al estado verdadero de \( H_0 \) (si es verdadera o falsa).
Los elementos a considerar en una prueba de hipótesis son:
Elemento |
Descripción breve |
|---|---|
Hipótesis \( H_0 \), \( H_a \) |
Planteamiento formal del contraste |
Nivel de significancia |
Umbral de decisión (\( \alpha \)) |
Estadístico de prueba |
Valor numérico basado en la muestra |
Distribución bajo \( H_0 \) |
Base para calcular el p-valor o valor crítico |
Regla de decisión |
Comparación entre estadístico/p-valor y \( \alpha \) |
Conclusión |
Aceptar o rechazar \( H_0 \), con interpretación contextual |
Análisis de errores |
Consideración de errores tipo I, tipo II y poder estadístico |
5.8. Test sobre una y dos muestras#
Se introducen dos funciones: stats.ttest_1samp y stats.wilcoxon para el test t y el test de Wilcoxon respectivamente. Ambos pueden ser usados para una muestra o dos muestras así como para datos pareados. Note que el test de Wilcoxon para dos muestras es lo mismo que el test de Mann–Whitney.
5.8.1. El test t#
Este test se basa en el supuesto de normalidad de los datos. Es decir que los datos \(x_1\ldots,x_n\) se asumen como realizaciones independientes de variables aleatorias con media \(\mu\) y varianza \(\sigma^2\), \(N(\mu, \sigma^2)\). Se tiene que la hipótesis nula es que \(\mu=\mu_0\).
Se puede estimar los parámetros \(\mu\) y \(\sigma\) por la media \(\bar{x}\) y la desviación estándar \(\sigma\), aunque recuerde que solo son estimaciones del valor real.
Veamos un ejemplo del consuo diario de calorías de 11 mujeres:
daily_intake = [5260,5470,5640,6180,6390,6515,
6805,7515,7515,8230,8770]
Veamos algunas estadísticas de resumen:
from scipy import stats
import numpy as np
stats.describe(daily_intake)
DescribeResult(nobs=11, minmax=(5260, 8770), mean=6753.636363636364, variance=1304445.4545454548, skewness=0.3674679616524392, kurtosis=-0.9757942883536157)
Se podría querer saber si el consumo de energía de las mujeres se desvía de una valor recomendado de \(7725\). Asumiendo que los datos vienen de una distribución normal, el objetivo es hacer una prueba para saber si la media de la distribución es \(\mu = 7725\).
stats.ttest_1samp(daily_intake,7725)
TtestResult(statistic=-2.8207540608310193, pvalue=0.018137235176105805, df=10)
t, pval = stats.ttest_1samp(daily_intake,7725)
t
-2.8207540608310193
pval
0.018137235176105805
5.8.2. Wilcoxon#
(rank, pVal) = stats.wilcoxon(x=(np.array(daily_intake)-7725))
(rank, pVal)
(8.0, 0.0244140625)
Para efectos prácticos, cuando se trata de una muestra, el test t y el de Wilcoxon suelen arrojar resultados muy similares.
5.9. Test t para dos muestras#
Se usa esta prueba con la hipótesis nula de que dos muestras provengan de distribuciones normales con la misma media.
Se puede tener dos enfoques, que las muestras tengan la misma varianza (enfoque clásico) o difieran en varianza.
import numpy as np
from scipy import stats
import pandas as pd
uu = "https://raw.githubusercontent.com/vmoprojs/DataLectures/master/energy.csv"
energy = pd.read_csv(uu)
energy.head()
| expend | stature | |
|---|---|---|
| 0 | 9.21 | obese |
| 1 | 7.53 | lean |
| 2 | 7.48 | lean |
| 3 | 8.08 | lean |
| 4 | 8.09 | lean |
g1 = energy[energy.stature=='obese'].expend.values
g2 = energy[energy.stature=='lean'].expend.values
stats.ttest_ind(g2,g1,equal_var=False)
TtestResult(statistic=-3.855503558973697, pvalue=0.0014106918447179043, df=15.91873619676766)
stats.ttest_ind(g2,g1,equal_var=True)
TtestResult(statistic=-3.9455649161549835, pvalue=0.0007989982111700593, df=20.0)
5.9.1. Comparación de varianzas#
Aún cuando en python se puede hacer la prueba sobre dos muestras sin el supuesto de igualdad en las varianzas, podrías estar interesado en hacer una prueba exclusiva de este supuesto.
import statistics
F = statistics.variance(g2)/statistics.variance(g1)
df1 = len(g1) - 1
df2 = len(g2) - 1
alpha = 0.05
p_value = stats.f.cdf(F, df2, df1)
(F,p_value*2)
(0.7844459792357035, 0.6797459853760682)
5.9.2. Test de Wilcoxon para dos muestras#
u_statistic, pVal = stats.mannwhitneyu(g1, g2)
(u_statistic, pVal*2)
(105.0, 0.004243226771760096)
5.10. KS Test#
Compara la distribución subyacente de dos muestras independientes \(F(x)\) y \(G(x)\). Es válidas solo para distribuciones continuas.
stats.kstest(g1,g2)
KstestResult(statistic=0.8461538461538461, pvalue=0.00026536930561698365, statistic_location=8.4, statistic_sign=-1)
stats.kstest(g1,stats.norm.cdf)
KstestResult(statistic=1.0, pvalue=0.0, statistic_location=8.79, statistic_sign=-1)
stats.kstest(g2,stats.norm.cdf)
KstestResult(statistic=0.9999999995606046, pvalue=4.5514700442308465e-122, statistic_location=6.13, statistic_sign=-1)
5.11. Correlación#
Se aborda a continuación medidas de correlación paramétricas y no paramétricas. El coeficiente de correlación es una medida de asociación que varía entre -1 y 1.
5.11.1. Correlación de Pearson#
El coeficiente de correlación empírico es:
La función cor en python calcula la correlación entre dos o más vectores.
uu = "https://raw.githubusercontent.com/vmoprojs/DataLectures/master/company_sales_data.csv"
import pandas as pd
datos = pd.read_csv(uu)
datos
| month_number | facecream | facewash | toothpaste | bathingsoap | shampoo | moisturizer | total_units | total_profit | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2500 | 1500 | 5200 | 9200 | 1200 | 1500 | 21100 | 211000 |
| 1 | 2 | 2630 | 1200 | 5100 | 6100 | 2100 | 1200 | 18330 | 183300 |
| 2 | 3 | 2140 | 1340 | 4550 | 9550 | 3550 | 1340 | 22470 | 224700 |
| 3 | 4 | 3400 | 1130 | 5870 | 8870 | 1870 | 1130 | 22270 | 222700 |
| 4 | 5 | 3600 | 1740 | 4560 | 7760 | 1560 | 1740 | 20960 | 209600 |
| 5 | 6 | 2760 | 1555 | 4890 | 7490 | 1890 | 1555 | 20140 | 201400 |
| 6 | 7 | 2980 | 1120 | 4780 | 8980 | 1780 | 1120 | 29550 | 295500 |
| 7 | 8 | 3700 | 1400 | 5860 | 9960 | 2860 | 1400 | 36140 | 361400 |
| 8 | 9 | 3540 | 1780 | 6100 | 8100 | 2100 | 1780 | 23400 | 234000 |
| 9 | 10 | 1990 | 1890 | 8300 | 10300 | 2300 | 1890 | 26670 | 266700 |
| 10 | 11 | 2340 | 2100 | 7300 | 13300 | 2400 | 2100 | 41280 | 412800 |
| 11 | 12 | 2900 | 1760 | 7400 | 14400 | 1800 | 1760 | 30020 | 300200 |
datos.plot('shampoo','bathingsoap',kind = 'scatter')
<Axes: xlabel='shampoo', ylabel='bathingsoap'>
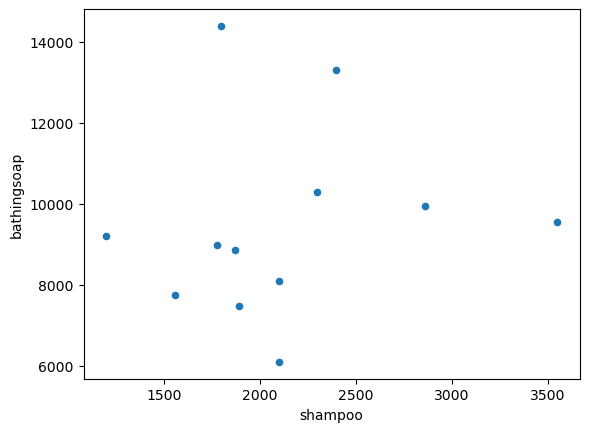
np.corrcoef(datos.shampoo,datos.bathingsoap)
array([[1. , 0.13756757],
[0.13756757, 1. ]])
stats.pearsonr(datos.shampoo,datos.bathingsoap) # devuelve la correlacion y el p-valor
PearsonRResult(statistic=0.1375675688230804, pvalue=0.6698531673457456)
stats.spearmanr(datos.shampoo,datos.bathingsoap) # Spearman's rho
SignificanceResult(statistic=0.2907184843604137, pvalue=0.35929281767147814)
stats.kendalltau(datos.shampoo,datos.bathingsoap) # Kendall's tau
SignificanceResult(statistic=0.10687334289668038, pvalue=0.6304167324095717)
Interpretación de la correlación:
La correlación esta siempre entre -1 y 1. Lo primero que se interpreta es el signo
Directamente proporcional si es positivo, si es negativo pasa lo contrario
En segundo lugar se interpreta es la fuerza de la relación. Si esta más cerca de 1, significa que si aumenta una variable, la otra también.
Números intermedios, reducen la fuerza de la relación.