10. Selección y regularización de modelos lineales#
A pesar de su simplicidad, los modelos lineales tienen ventajas de interpretabilidad y con frecuencia muestran buen rendimiento en predicción
Esta sección aborda el cambiar el ajuste de mínimos cuadrados ordinarios (OLS) tradicional por métodos alternativos que se apalancan en OLS.
¿Por que usar alternativas a OLS?
Predictibilidad: Si la relación entre las variables es aproximadamente lineal y si \(n\gg p\) (el número de observaciones es más grande que el número de variables), entonces OLS tiene poco sesgo y rinde bien en datos test. Sin embargo, si \(n\) no es tan grande respecto a \(p\), puede haber mucha variabilidad en OLS, lo que resulta en sobreajuste y mal rendimiento en test.
Algunos de los problemas que surgen cuando \(n\approx p\):
Sobreajuste (Overfitting)
El error cuadrático medio (MSE) en el conjunto de entrenamiento se define como:
donde:
\( y_i \) es el valor observado,
\( \hat{y}_i \) es la predicción del modelo,
\( n \) es el número de observaciones.
Cuando el número de variables \(p\) se aproxima a \(n\), el modelo puede ajustarse casi perfectamente, lo que minimiza el MSE en el conjunto de entrenamiento, pero aumenta el error en nuevos datos (error de generalización). Este es el problema del sobreajuste.
Multicolinealidad
El problema de multicolinealidad se detecta cuando las variables explicativas están altamente correlacionadas entre sí. Un indicador común es el Factor de Inflación de la Varianza (VIF) para cada variable \(j\), que se define como:
donde \( R_j^2 \) es el coeficiente de determinación de la regresión de la variable \( X_j \) sobre todas las demás variables.
Cuando \( VIF_j \) es grande (mayor a 10, por ejemplo), indica una alta colinealidad. Esto causa inestabilidad en las estimaciones de los coeficientes \( \hat{\beta}_j \), lo que puede hacer que el modelo sea sensible a pequeños cambios en los datos.
Modelo No Identificable
En regresión lineal, los coeficientes de los parámetros \( \boldsymbol{\beta} = (\beta_1, \beta_2, \dots, \beta_p) \) se obtienen resolviendo el sistema de ecuaciones lineales:
donde:
\( \boldsymbol{y} \) es el vector de observaciones (de dimensión \( n \times 1 \)),
\( \mathbf{X} \) es la matriz de diseño (de dimensión \( n \times p \)),
\( \boldsymbol{\beta} \) es el vector de coeficientes,
\( \boldsymbol{\epsilon} \) es el término de error.
Para resolver \( \boldsymbol{\beta} \), necesitamos invertir la matriz \( \mathbf{X}^T \mathbf{X} \). Si \( p \geq n \), la matriz \( \mathbf{X}^T \mathbf{X} \) no es invertible, lo que significa que el sistema es no identificable y no existe una única solución para \( \boldsymbol{\beta} \).
Varianza Alta
Cuando hay más variables que observaciones, el error estándar de los coeficientes de regresión se incrementa. La varianza de los coeficientes \( \hat{\beta}_j \) está dada por:
donde \( \sigma^2 \) es la varianza del error residual. Si \( \mathbf{X}^T \mathbf{X} \) es mal condicionada (debido a la colinealidad o alta dimensionalidad), los elementos de la matriz inversa \( (\mathbf{X}^T \mathbf{X})^{-1} \) pueden ser muy grandes, lo que resulta en una varianza elevada para \(\hat{\beta}_j\). Esto significa que los coeficientes son altamente sensibles a los cambios en los datos.
Interpretabilidad: Incluir variables independientes sin asociación con la variable dependiente en un modelo de regresión resulta en incluir complejidades innecesarias en el modelo. Si son removidas (se fijan sus coeficientes en cero), se puede obtener un modelo que es más interpretable. En OLS hay muy poca probabilidad de que se tengan coeficientes iguales a cero. Al eliminar variables estamos haciendo selección de variables o feature selection: selección de variables, contracción o regularización y reducción de dimensionalidad.
10.1. Selección de variables#
10.1.1. Selección de las mejores variables#
Algoritmo: Selección de las mejores variables |
|---|
1. Sea \(\mathcal{M_0}\) el modelo nulo (sin predictores). Este modelo solo predice la media muestral para cada observación. |
2. Para \(k = 1,2,\ldots,p\): |
|
|
3. Selecciona el mejor modelo de los \(\mathcal{M_0},\ldots,\mathcal{M_p}\) usando el error de predicción en un conjunto de validación, \(C_p\), AIC, BIC o \(R^2\) ajustado. O usa el método de validación cruzada. |
Ejemplo
Supón que tienes estas variables para predecir nota final (nota que \(p=5\)):
horas_estudio, uso_internet, nivel_socio, edad, género
Nota que en este caso tendrías la siguiente cantidad de modelos a probar:
En cada \(k\), tendrás una elección final de todas las posibles:
Modelo |
k |
C(5, k) |
Ejemplo de variables |
Resultado |
|---|---|---|---|---|
\(M_0\) |
0 |
1 |
Ninguna (modelo nulo) |
Promedio general |
\(M_1\) |
1 |
5 |
horas_estudio |
Mejor entre 5 modelos con 1 variable |
\(M_2\) |
2 |
10 |
horas_estudio + uso_internet |
Mejor entre 10 modelos con 2 variables |
\(M_3\) |
3 |
10 |
horas_estudio + uso_internet + edad |
Mejor entre 10 modelos con 3 variables |
\(M_4\) |
4 |
5 |
horas_estudio + uso_internet + edad + género |
Mejor entre 5 modelos con 4 variables |
\(M_5\) |
5 |
1 |
Todas (modelo completo) |
Único modelo con todas las variables |
Nota que este algoritmo no puede ser aplicado cuando \(p\) es grande.
También puede tener problemas de estadísticos cuando \(p\) es grande. Cuanto mayor sea el espacio de búsqueda, mayor será la posibilidad de encontrar modelos que se vean bien en los datos de entrenamiento, aunque podrían no tener ningún poder predictivo sobre datos futuros.
Por lo tanto, un espacio de búsqueda enorme puede dar lugar a un sobreajuste y a una alta varianza de las estimaciones de los coeficientes.
Por los motivos antes listado, los métodos stepwise o paso a paso son más atractivos.
\(C_p\) de Mallow
donde \(d\) es el total de parámetros usados y \(\hat{\sigma}^2\) es la estimación de la varianza del error \(\epsilon\).
Criterio AIC
Se puede usar en modelos donde el ajuste se realiza con máxima verosimilitud:
Donde \(L\) es el valor máximo de la función de máxima verosimilitud del modelo.
donde \(n\) es el número de observaciones.
\(R^2\) ajustado
donde \(TSS\) es la suma total de cuadrados.
10.1.2. Selección stepwise hacia adelante#
Algoritmo: Selección stepwise hacia adelante |
|---|
1. Sea \(\mathcal{M_0}\) el modelo nulo (sin predictores). Este modelo solo predice la media muestral para cada observación. |
2. Para \(k = 0,2,\ldots,p-1\): |
|
|
3. Selecciona el mejor modelo de los \(\mathcal{M_0},\ldots,\mathcal{M_p}\) usando el error de predicción en un conjunto de validación, \(C_p\), AIC, BIC o \(R^2\) ajustado. O usa el método de validación cruzada. |
Ejemplo
Supón que tienes estas variables para predecir nota final (nota que \(p=5\)):
horas_estudio, uso_internet, nivel_socio, edad, género
Empiezas sin ninguna \(\rightarrow\) \(M_0\)
Pruebas una por una \(\rightarrow\) eliges la mejor \(\rightarrow\) \(M_1\) (
nota ~ horas_estudio)Agregas otra de las restantes \(\rightarrow\) eliges la mejor \(\rightarrow\) \(M_2\) (
nota ~ horas_estudio + uso_internet)Sigues así hasta probar todas
Eliges el mejor modelo entre todos (\(M_0\) a \(M_5\)), usando validación cruzada o AIC/BIC
10.1.3. Selección stepwise hacia atrás#
Algoritmo: Selección stepwise hacia atrás |
|---|
1. Sea \(\mathcal{M_p}\) el modelo completo, que contiene todos los \(p\) predictores. |
2. Para \(k = p,p-1,\ldots,1\): |
|
|
3. Selecciona el mejor modelo de los \(\mathcal{M_0},\ldots,\mathcal{M_p}\) usando el error de predicción en un conjunto de validación, \(C_p\), AIC, BIC o \(R^2\) ajustado. O usa el método de validación cruzada. |
Ejemplo
Supón que tienes estas variables para predecir nota final (nota que \(p=5\)):
horas_estudio, uso_internet, nivel_socio, edad, género
Empiezas con todas \(\rightarrow\) \(M_5\)
Pruebas quitando una por una \(\rightarrow\) eliges la mejor \(\rightarrow\) \(M_4\) (
nota ~ horas_estudio + uso_internet + nivel_socio + edad). Aquí, por ejemplo, quitargéneroresultó ser la mejor opción.Manteniendo \(M_4\), quitas otra de las restantes \(\rightarrow\) eliges la mejor \(\rightarrow\) \(M_3\) (
nota ~ uso_internet + nivel_socio + edad). Aquí, por ejemplo, quitarhoras_estudioresultó ser la mejor opción.Sigues así hasta probar quitnato todas
Eliges el mejor modelo entre todos (\(M_0\) a \(M_5\)), usando validación cruzada o AIC/BIC
10.1.3.1. Ejemplo#
La superintendencia de compañias del Ecuador tiene información de estados financieros de las empresas que regula. Vamos a predecir los ingresos por ventas de las empresas grandes del 2023. En la pestaña Recursos del siguiente enlace: https://appscvsmovil.supercias.gob.ec/ranking/reporte.html
import pandas as pd
import statsmodels.api as sm
uu = "https://raw.githubusercontent.com/vmoprojs/DataLectures/refs/heads/master/superciasGrandes2023.csv"
datos = pd.read_csv(uu)
datos.drop(columns = ['Unnamed: 0'],inplace = True)
# Supongamos que 'X' es tu conjunto de características y 'y' la variable dependiente.
X = datos.loc[:,datos.columns!='ingresos_ventas'] # tus datos de características
X = X.loc[:,X.columns!='costos_ventas_prod']
y = datos['ingresos_ventas']/1000000 # tu variable dependiente
#import sweetviz as sv
#my_report = sv.analyze(datos)
#my_report.show_html()# altas correlaciones
Notamos que existen variables con alta correlación, se eliminan correlaciones superiores a \(0.9\).
# Importa la librería NumPy, necesaria para operaciones numéricas con matrices y arrays
import numpy as np
# Calcula la matriz de correlación de Pearson entre las variables de X (entre -1 y 1),
# y toma el valor absoluto para enfocarse solo en la fuerza de la relación (no en su dirección)
corr_matrix = X.corr().abs()
# Crea una matriz triangular superior (sin la diagonal) para evitar duplicados y la diagonal en la correlación
# np.triu(...) genera una matriz de unos en la parte superior, luego se convierte en booleano para usarla como máscara
upper_triangle = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(bool))
# Recorre las columnas y selecciona aquellas que tienen al menos una correlación alta (> 0.8) con otra variable
high_corr_columns = [
column for column in upper_triangle.columns
if any(upper_triangle[column] > 0.8)
]
# Elimina del conjunto de datos X las columnas con alta correlación detectadas en el paso anterior
X = X.drop(columns=high_corr_columns)
# Imprime en consola la lista de nombres de las columnas que fueron eliminadas por estar altamente correlacionadas
print("Columnas eliminadas por alta correlación:\n", high_corr_columns)
Columnas eliminadas por alta correlación:
['patrimonio', 'impuesto_renta', 'utilidad_ejercicio', 'utilidad_neta', 'prueba_acida', 'end_largo_plazo', 'apalancamiento', 'apalancamiento_c_l_plazo', 'rot_activo_fijo', 'rent_ope_activo', 'roa', 'total_gastos']
start_model = sm.OLS(y, X).fit()
print(start_model.summary())
OLS Regression Results
=======================================================================================
Dep. Variable: ingresos_ventas R-squared (uncentered): 0.818
Model: OLS Adj. R-squared (uncentered): 0.816
Method: Least Squares F-statistic: 425.0
Date: Wed, 04 Jun 2025 Prob (F-statistic): 0.00
Time: 06:05:34 Log-Likelihood: -15624.
No. Observations: 2969 AIC: 3.131e+04
Df Residuals: 2938 BIC: 3.150e+04
Df Model: 31
Covariance Type: nonrobust
=============================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------------------
activos 4.267e-07 1.98e-08 21.527 0.000 3.88e-07 4.66e-07
utilidad_an_imp 2.59e-07 8.59e-08 3.017 0.003 9.07e-08 4.27e-07
n_empleados 0.0252 0.002 13.497 0.000 0.022 0.029
liquidez_corriente 0.0171 0.014 1.227 0.220 -0.010 0.044
end_activo -0.1281 1.138 -0.113 0.910 -2.359 2.103
end_patrimonial -0.0379 0.089 -0.426 0.670 -0.212 0.136
end_activo_fijo -1.679e-05 5.77e-05 -0.291 0.771 -0.000 9.64e-05
end_corto_plazo 21.5596 1.986 10.855 0.000 17.665 25.454
cobertura_interes 4.176e-06 7.97e-06 0.524 0.600 -1.14e-05 1.98e-05
apalancamiento_financiero -0.0020 0.005 -0.403 0.687 -0.011 0.008
end_patrimonial_ct -0.0012 0.150 -0.008 0.994 -0.295 0.292
end_patrimonial_nct 0.6346 0.577 1.100 0.271 -0.496 1.765
rot_cartera 1.821e-05 1.95e-05 0.932 0.352 -2.01e-05 5.65e-05
rot_ventas 0.0416 0.039 1.078 0.281 -0.034 0.117
per_med_cobranza -8.883e-07 5.97e-07 -1.488 0.137 -2.06e-06 2.83e-07
per_med_pago 1.7e-08 1.25e-08 1.361 0.174 -7.49e-09 4.15e-08
impac_gasto_a_v -1.5197 0.725 -2.096 0.036 -2.941 -0.098
impac_carga_finan -107.0103 22.392 -4.779 0.000 -150.917 -63.104
rent_neta_activo 14.2754 5.624 2.539 0.011 3.249 25.302
margen_bruto -27.5007 3.178 -8.654 0.000 -33.732 -21.270
margen_operacional 6.395e-08 1.5e-08 4.254 0.000 3.45e-08 9.34e-08
rent_neta_ventas -32.6691 7.673 -4.258 0.000 -47.713 -17.625
rent_ope_patrimonio -0.0029 0.012 -0.236 0.814 -0.027 0.021
roe 0.0333 0.055 0.604 0.546 -0.075 0.141
fortaleza_patrimonial -0.4488 0.758 -0.592 0.554 -1.934 1.037
gastos_financieros 1.278e-06 4.1e-07 3.116 0.002 4.74e-07 2.08e-06
gastos_admin_ventas 1.142e-06 7.42e-08 15.384 0.000 9.96e-07 1.29e-06
depreciaciones -7.185e-07 5e-07 -1.437 0.151 -1.7e-06 2.62e-07
amortizaciones -3.584e-06 6.33e-07 -5.665 0.000 -4.82e-06 -2.34e-06
deuda_total 2.197e-06 1.38e-07 15.935 0.000 1.93e-06 2.47e-06
deuda_total_c_plazo 4.409e-06 4.75e-07 9.275 0.000 3.48e-06 5.34e-06
==============================================================================
Omnibus: 4187.902 Durbin-Watson: 2.054
Prob(Omnibus): 0.000 Jarque-Bera (JB): 2749251.147
Skew: 7.826 Prob(JB): 0.00
Kurtosis: 151.252 Cond. No. 3.07e+09
==============================================================================
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[3] The condition number is large, 3.07e+09. This might indicate that there are
strong multicollinearity or other numerical problems.
Evaluación del modelo
# Importación de funciones métricas desde scikit-learn para evaluar modelos de regresión
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# Definición de una función personalizada para evaluar un modelo de regresión
def evaluate_model(y_true, y_pred):
# Cálculo del error absoluto medio: promedio de las diferencias absolutas entre observados y predichos
mae = mean_absolute_error(y_true, y_pred)
# Cálculo del error cuadrático medio: promedio de los cuadrados de las diferencias
mse = mean_squared_error(y_true, y_pred)
# Cálculo de la raíz del error cuadrático medio: facilita la interpretación porque está en las mismas unidades que la variable objetivo
rmse = np.sqrt(mse)
# Cálculo del coeficiente de determinación R²: indica la proporción de varianza explicada por el modelo
r2 = r2_score(y_true, y_pred)
# Retorna las cuatro métricas de evaluación como una tupla
return mae, mse, rmse, r2
# Predicción de los valores utilizando un modelo OLS previamente entrenado llamado 'start_model'
y_pred_ols = start_model.predict(X)
# Evaluación del modelo OLS comparando las predicciones con los valores reales (y)
# Almacena cada métrica en una variable correspondiente
mae_ols, mse_ols, rmse_ols, r2_ols = evaluate_model(y, y_pred_ols)
# Impresión de los resultados de evaluación del modelo OLS
print("\nOLS Métricas de evaluación:")
# Error absoluto medio con dos decimales
print(f"Mean Absolute Error (MAE): {mae_ols:.2f}")
# Error cuadrático medio con dos decimales
print(f"Mean Squared Error (MSE): {mse_ols:.2f}")
# Raíz del error cuadrático medio con dos decimales
print(f"Root Mean Squared Error (RMSE): {rmse_ols:.2f}")
# Coeficiente R² con dos decimales
print(f"R-squared: {r2_ols:.2f}")
OLS Métricas de evaluación:
Mean Absolute Error (MAE): 16.09
Mean Squared Error (MSE): 2179.19
Root Mean Squared Error (RMSE): 46.68
R-squared: 0.80
Modelo hacia adelante:
# Importación del selector secuencial de características desde sklearn y el modelo de regresión lineal
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.linear_model import LinearRegression
# Crear el modelo base: una regresión lineal ordinaria (no regularizada)
model = LinearRegression()
# Crear el selector de características secuencial:
# - Usa el modelo lineal como evaluador
# - 'forward' indica que se agregan características una a una (selección hacia adelante)
# - n_features_to_select='auto' permite que el selector determine automáticamente cuántas características son óptimas
sfs = SequentialFeatureSelector(model, n_features_to_select='auto', direction='forward')
# Ajusta el selector a los datos: evalúa distintas combinaciones de variables para encontrar el mejor subconjunto
sfs.fit(X, y)
# Extrae un array booleano que indica qué variables fueron seleccionadas (True = seleccionada)
selected_features = sfs.get_support()
# Filtra X para quedarse solo con las columnas seleccionadas
X_selected = X.loc[:, selected_features]
# Ajusta un modelo OLS (de statsmodels) con las variables seleccionadas
# Nota: 'sm' debe estar previamente importado como: import statsmodels.api as sm
final_model = sm.OLS(y, X_selected).fit()
# Muestra el resumen completo del modelo OLS: incluye coeficientes, R², p-valores, etc.
print(final_model.summary())
OLS Regression Results
=======================================================================================
Dep. Variable: ingresos_ventas R-squared (uncentered): 0.811
Model: OLS Adj. R-squared (uncentered): 0.810
Method: Least Squares F-statistic: 842.7
Date: Wed, 04 Jun 2025 Prob (F-statistic): 0.00
Time: 06:05:35 Log-Likelihood: -15680.
No. Observations: 2969 AIC: 3.139e+04
Df Residuals: 2954 BIC: 3.148e+04
Df Model: 15
Covariance Type: nonrobust
=========================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------------
activos 4.878e-07 1.4e-08 34.946 0.000 4.6e-07 5.15e-07
n_empleados 0.0208 0.002 12.851 0.000 0.018 0.024
end_corto_plazo 22.2718 1.836 12.130 0.000 18.672 25.872
end_patrimonial_ct -0.0346 0.086 -0.401 0.689 -0.204 0.135
rot_cartera 1.94e-05 1.98e-05 0.978 0.328 -1.95e-05 5.83e-05
per_med_pago 1.367e-08 1.26e-08 1.080 0.280 -1.11e-08 3.85e-08
impac_gasto_a_v -1.5230 0.731 -2.082 0.037 -2.957 -0.089
impac_carga_finan -98.7982 21.518 -4.591 0.000 -140.990 -56.606
rent_neta_activo 17.6911 5.258 3.364 0.001 7.381 28.001
margen_bruto -25.7358 3.143 -8.189 0.000 -31.898 -19.573
rent_neta_ventas -35.7664 7.223 -4.952 0.000 -49.928 -21.604
fortaleza_patrimonial -0.8198 0.719 -1.140 0.254 -2.230 0.591
gastos_admin_ventas 9.447e-07 5.34e-08 17.702 0.000 8.4e-07 1.05e-06
deuda_total 2.124e-06 1.33e-07 16.029 0.000 1.86e-06 2.38e-06
deuda_total_c_plazo 4.96e-06 4.71e-07 10.530 0.000 4.04e-06 5.88e-06
==============================================================================
Omnibus: 4174.333 Durbin-Watson: 2.035
Prob(Omnibus): 0.000 Jarque-Bera (JB): 2485003.183
Skew: 7.817 Prob(JB): 0.00
Kurtosis: 143.866 Cond. No. 2.81e+09
==============================================================================
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[3] The condition number is large, 2.81e+09. This might indicate that there are
strong multicollinearity or other numerical problems.
# Realiza predicciones sobre el conjunto de entrenamiento utilizando el modelo final ajustado con las variables seleccionadas
# 'X_selected' contiene solo las variables elegidas por el proceso de selección secuencial hacia adelante
y_pred_adelante = final_model.predict(X_selected)
# Evalúa el desempeño del modelo usando la función 'evaluate_model' previamente definida
# Calcula: MAE (error absoluto medio), MSE (error cuadrático medio), RMSE (raíz del error cuadrático medio) y R² (coeficiente de determinación)
mae_adelante, mse_adelante, rmse_adelante, r2_adelante = evaluate_model(y, y_pred_adelante)
# Imprime en consola las métricas de evaluación del modelo construido tras la selección hacia adelante
print("\n(Adelante) Métricas de evaluación:")
# Error absoluto medio
print(f"Mean Absolute Error (MAE): {mae_adelante:.2f}")
# Error cuadrático medio
print(f"Mean Squared Error (MSE): {mse_adelante:.2f}")
# Raíz del error cuadrático medio
print(f"Root Mean Squared Error (RMSE): {rmse_adelante:.2f}")
# Coeficiente R²
print(f"R-squared: {r2_adelante:.2f}")
(Adelante) Métricas de evaluación:
Mean Absolute Error (MAE): 16.51
Mean Squared Error (MSE): 2263.94
Root Mean Squared Error (RMSE): 47.58
R-squared: 0.79
Modelo hacia atrás
# Importación del selector secuencial de características desde scikit-learn y del modelo de regresión lineal
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.linear_model import LinearRegression
# Crear el modelo base: en este caso, una regresión lineal ordinaria
model = LinearRegression()
# Crear el selector de características secuencial con selección hacia atrás
# - El modelo 'model' se usa para evaluar qué variables eliminar
# - 'direction="backward"' indica que el selector comienza con todas las variables y elimina una por una
# - 'n_features_to_select="auto"' permite que el selector determine automáticamente cuántas conservar (basado en validación cruzada)
sfs = SequentialFeatureSelector(model, n_features_to_select='auto', direction='backward')
# Ajusta el selector de características a los datos
# Internamente realiza múltiples ajustes del modelo eliminando variables una a una
sfs.fit(X, y)
# Obtiene un array booleano que indica cuáles variables fueron finalmente seleccionadas (True = seleccionada)
selected_features = sfs.get_support()
# Filtra el DataFrame X para mantener solo las variables seleccionadas
X_selected = X.loc[:, selected_features]
# Ajusta un modelo de regresión OLS usando statsmodels con las variables seleccionadas
# Esto permite obtener un resumen estadístico completo del modelo (coeficientes, p-valores, etc.)
final_model = sm.OLS(y, X_selected).fit()
# Imprime el resumen estadístico del modelo final seleccionado
print(final_model.summary())
OLS Regression Results
=======================================================================================
Dep. Variable: ingresos_ventas R-squared (uncentered): 0.810
Model: OLS Adj. R-squared (uncentered): 0.809
Method: Least Squares F-statistic: 787.0
Date: Wed, 04 Jun 2025 Prob (F-statistic): 0.00
Time: 06:05:38 Log-Likelihood: -15685.
No. Observations: 2969 AIC: 3.140e+04
Df Residuals: 2953 BIC: 3.150e+04
Df Model: 16
Covariance Type: nonrobust
=======================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------------
activos 4.838e-07 1.39e-08 34.757 0.000 4.56e-07 5.11e-07
n_empleados 0.0209 0.002 12.916 0.000 0.018 0.024
end_patrimonial -0.0832 0.088 -0.946 0.344 -0.256 0.089
end_corto_plazo 23.6055 1.800 13.114 0.000 20.076 27.135
end_patrimonial_ct 0.0500 0.142 0.353 0.724 -0.228 0.328
end_patrimonial_nct 0.6900 0.586 1.177 0.239 -0.460 1.840
rot_cartera 2.081e-05 1.99e-05 1.048 0.295 -1.81e-05 5.98e-05
per_med_pago 1.239e-08 1.27e-08 0.977 0.329 -1.25e-08 3.73e-08
impac_gasto_a_v -1.5354 0.733 -2.093 0.036 -2.973 -0.097
impac_carga_finan -102.0002 21.526 -4.738 0.000 -144.208 -59.793
margen_bruto -25.6326 3.150 -8.138 0.000 -31.809 -19.457
rent_neta_ventas -29.5289 6.929 -4.261 0.000 -43.116 -15.942
roe 0.0675 0.042 1.608 0.108 -0.015 0.150
gastos_admin_ventas 9.57e-07 5.33e-08 17.964 0.000 8.53e-07 1.06e-06
deuda_total 2.121e-06 1.33e-07 15.981 0.000 1.86e-06 2.38e-06
deuda_total_c_plazo 4.953e-06 4.72e-07 10.498 0.000 4.03e-06 5.88e-06
==============================================================================
Omnibus: 4163.035 Durbin-Watson: 2.040
Prob(Omnibus): 0.000 Jarque-Bera (JB): 2455536.160
Skew: 7.777 Prob(JB): 0.00
Kurtosis: 143.027 Cond. No. 2.81e+09
==============================================================================
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[3] The condition number is large, 2.81e+09. This might indicate that there are
strong multicollinearity or other numerical problems.
# Predicciones y evaluación para Atras
y_pred_atras = final_model.predict(X_selected)
mae_atras, mse_atras, rmse_atras, r2_atras = evaluate_model(y, y_pred_atras)
# Mostrar evaluación
print("\n(Atrás) Métricas de evaluación:")
print(f"Mean Absolute Error (MAE): {mae_atras:.2f}")
print(f"Mean Squared Error (MSE): {mse_atras:.2f}")
print(f"Root Mean Squared Error (RMSE): {rmse_atras:.2f}")
print(f"R-squared: {r2_atras:.2f}")
(Atrás) Métricas de evaluación:
Mean Absolute Error (MAE): 16.66
Mean Squared Error (MSE): 2270.38
Root Mean Squared Error (RMSE): 47.65
R-squared: 0.79
10.2. Regularización#
10.2.1. Introducción#
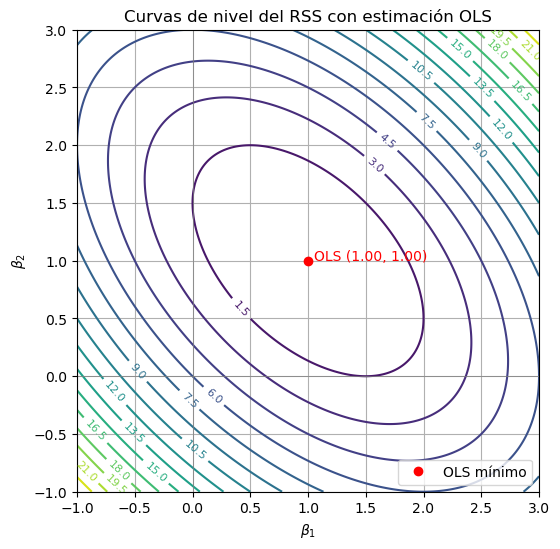
Las curvas de nivel (o superficies en dimensiones mayores) de la función de pérdida del modelo, usualmente el error cuadrático residual (RSS) en regresión lineal:
Un contorno es el conjunto de puntos \( \boldsymbol{\beta} \) donde la función de pérdida tiene el mismo valor:
La función de pérdida como elipses
La función \( \text{RSS}(\boldsymbol{\beta}) \) es una función cuadrática convexa respecto a \( \boldsymbol{\beta} \), y se puede reescribir matricialmente como:
Esto da lugar a:
Esta es una forma cuadrática en \( \boldsymbol{\beta} \), lo cual en geometría implica que sus curvas de nivel son elipses (o hiperesferas si los predictores están ortogonalizados y escalados).
Intuición geométrica
Cada elipse representa un nivel constante de error de predicción.
El centro de las elipses es el estimador de mínimos cuadrados \( \boldsymbol{\beta}_{\text{OLS}} \).
La forma y orientación de las elipses depende de la matriz \( \mathbf{X}^\top \mathbf{X} \), es decir, de la correlación entre predictores.
En 2D (por ejemplo, \( \beta_1 \), \( \beta_2 \)), si hay correlación, las elipses están inclinadas.
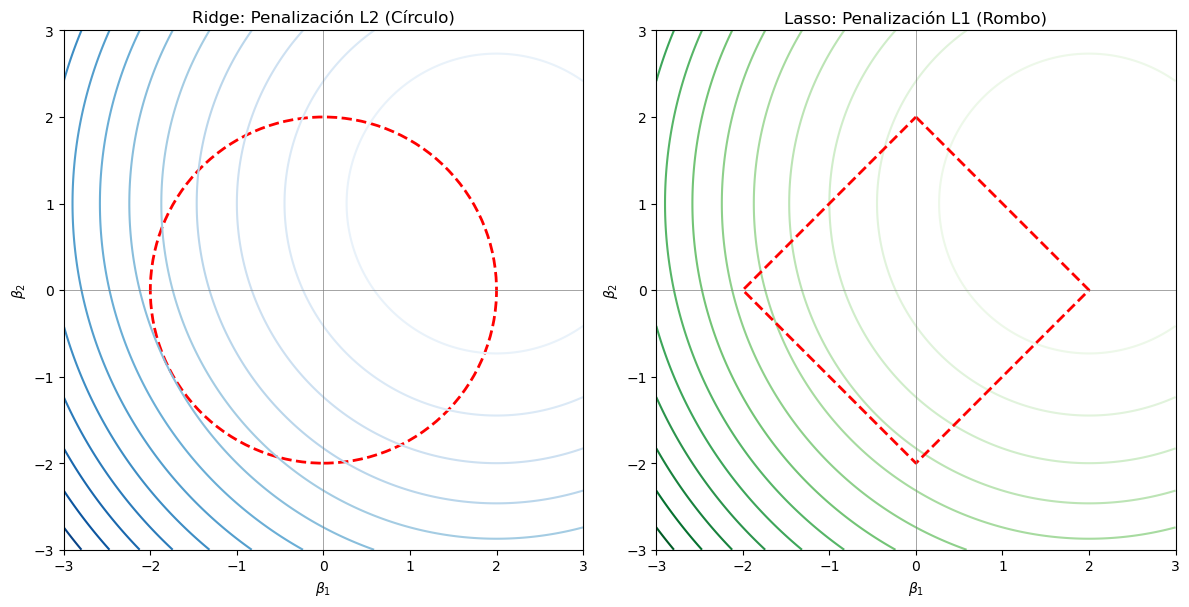
¿Por qué esto es útil para Ridge y Lasso?
Al aplicar penalización:
Se superpone una región de restricciones sobre los coeficientes:
Un círculo en Ridge (penalización L2).
Un rombo en Lasso (penalización L1).
El valor óptimo de \( \boldsymbol{\beta} \) es el punto donde el primer contorno toca esa región de penalización (intersección tangente).
10.2.1.1. Ejemplo#
Supongamos que tenemos el siguiente modelo:
\( y = \beta_1 x_1 + \beta_2 x_2 \)
Y que nuestra matriz de diseño \( \mathbf{X} \) y el vector de respuesta \( \mathbf{y} \) son:
La función de pérdida (RSS) es:
Podemos escribirla explícitamente:
Expandiendo los términos:
Agrupando términos, obtenemos una forma cuadrática en \( \beta_1 \) y \( \beta_2 \). En geometría, esta clase de expresiones define una cónica, y si la forma es convexa (como aquí, donde todos los coeficientes cuadráticos son positivos), la cónica resultante es una elipse.
Nota que
que corresponde a la forma general de una cónica:
import numpy as np
import matplotlib.pyplot as plt
# Matriz X y vector y
XX = np.array([[1, 0],
[0, 1],
[1, 1]])
yy = np.array([1, 1, 2])
# Estimación OLS: (X'X)^(-1) X'y
XtX = XX.T @ XX
Xty = XX.T @ yy
beta_ols = np.linalg.inv(XtX) @ Xty
beta1_hat, beta2_hat = beta_ols
# Crear grilla para beta1 y beta2
beta1 = np.linspace(-1, 3, 400)
beta2 = np.linspace(-1, 3, 400)
B1, B2 = np.meshgrid(beta1, beta2)
# Calcular el RSS para cada combinación
RSS = (1 - B1)**2 + (1 - B2)**2 + (2 - B1 - B2)**2
# Graficar
plt.figure(figsize=(6, 6))
contours = plt.contour(B1, B2, RSS, levels=20, cmap='viridis')
plt.clabel(contours, inline=True, fontsize=8)
plt.axhline(0, color='gray', lw=0.5)
plt.axvline(0, color='gray', lw=0.5)
# Punto OLS
plt.plot(beta1_hat, beta2_hat, 'ro', label='OLS mínimo')
plt.text(beta1_hat + 0.05, beta2_hat, f"OLS ({beta1_hat:.2f}, {beta2_hat:.2f})", color='red')
plt.xlabel(r"$\beta_1$")
plt.ylabel(r"$\beta_2$")
plt.title("Curvas de nivel del RSS con estimación OLS")
plt.gca().set_aspect('equal')
plt.grid(True)
plt.legend()
plt.show()
10.2.2. Un contexto más general#
La regularización es un método que nos permite restringir el proceso de estimación, se usa para evitar un posible sobre ajuste del modelo (overfitting).
Una forma de hacer regularización es donde los coeficientes de variables en el modelo no sean muy grandes (regresión ridge). Otra forma es contraer los coeficientes, llegando a tener coeficientes iguales a cero (regresión lasso).
Como regla general, el segundo enfoque suele ser mejor que el primero.
Los coeficientes regularizados se obtiene usando una función de penalidad \(p(\boldsymbol{\alpha})\) para restringir el tamaño del vector de coeficientes \(\boldsymbol{\alpha} = (\alpha_1,\cdots,\alpha_M)^T\) del predictor \(f(\mathbf{x}) = \sum_{j = 1}^{M} \alpha_jC_j(\mathbf{x})\). Los coeficientes penalizados son obtenidos como solución al problema de minimización:
donde \(L\) es una función de pérdida y \(\lambda>0\) es un parámetro de regularización también conocido como ratio de aprendizaje.
Existen diferentes opciones para funciones de pérdida:
Exponencial:
Logística:
Error cuadrático:
Error absoluto:
Huber
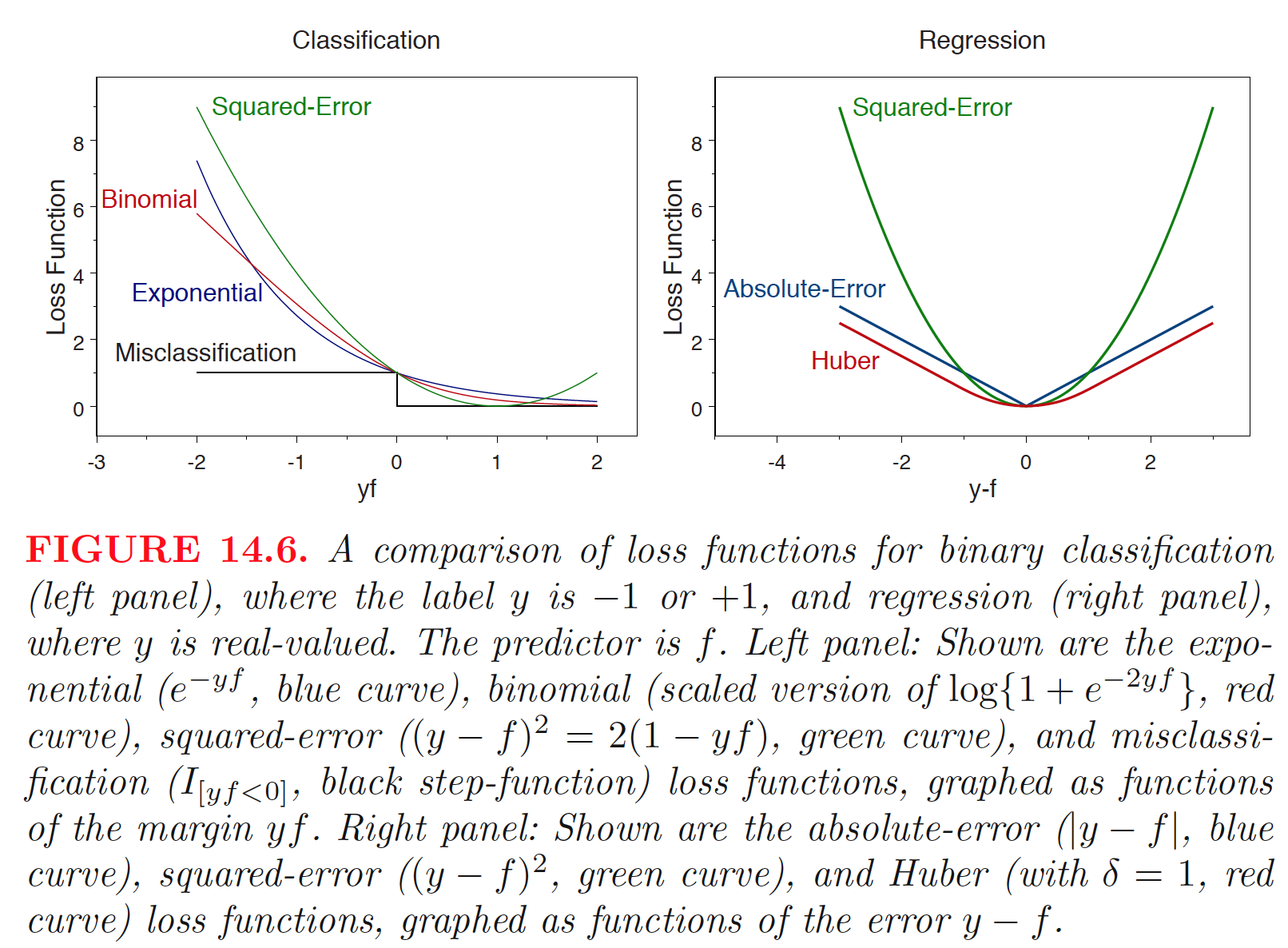
Hay dos tipos de funciones de penalidad:
\(L_2\): esta función de penalidad restringe la suma de cuadrados de los coeficientes,
Cuando \(L\) combinado es una combinación convexa y usamos la pérdida de error cuadrático, el predictor de regresión penalizado óptimo es el estimador de regresión ridge.
\(L_1\): Los coeficientes se restringen tal que su suma de valores absolutos,
sea menor que un valor dado. La evidencia empírica sugiere que la penalización \(L_1\) (lasso) funciona mejor cuando hay un número pequeño o mediano de coeficientes verdaderos de tamaño moderado.
import numpy as np
import matplotlib.pyplot as plt
# Crear una cuadrícula de valores para beta1 y beta2
beta1 = np.linspace(-3, 3, 400)
beta2 = np.linspace(-3, 3, 400)
B1, B2 = np.meshgrid(beta1, beta2)
# Simular una función de pérdida cuadrática (RSS) con mínimos en (2, 1)
RSS = (B1 - 2)**2 + (B2 - 1)**2
# Crear la figura
fig, axs = plt.subplots(1, 2, figsize=(12, 6))
# -------- Ridge (L2) --------
axs[0].contour(B1, B2, RSS, levels=15, cmap='Blues')
circle = plt.Circle((0, 0), 2, color='red', fill=False, linewidth=2, linestyle='--')
axs[0].add_artist(circle)
axs[0].set_title("Ridge: Penalización L2 (Círculo)")
axs[0].set_xlabel(r"$\beta_1$")
axs[0].set_ylabel(r"$\beta_2$")
axs[0].axhline(0, color='gray', linewidth=0.5)
axs[0].axvline(0, color='gray', linewidth=0.5)
axs[0].set_aspect('equal')
axs[0].set_xlim(-3, 3)
axs[0].set_ylim(-3, 3)
# -------- Lasso (L1) --------
axs[1].contour(B1, B2, RSS, levels=15, cmap='Greens')
# Dibujar el rombo para la norma L1 (|β1| + |β2| ≤ 2)
l1_boundary = np.array([
[0, 2], [2, 0], [0, -2], [-2, 0], [0, 2]
])
axs[1].plot(l1_boundary[:, 0], l1_boundary[:, 1], color='red', linestyle='--', linewidth=2)
axs[1].set_title("Lasso: Penalización L1 (Rombo)")
axs[1].set_xlabel(r"$\beta_1$")
axs[1].set_ylabel(r"$\beta_2$")
axs[1].axhline(0, color='gray', linewidth=0.5)
axs[1].axvline(0, color='gray', linewidth=0.5)
axs[1].set_aspect('equal')
axs[1].set_xlim(-3, 3)
axs[1].set_ylim(-3, 3)
plt.tight_layout()
plt.show()
10.2.3. Regresión Ridge#
En mínimos cuadrados ordinarios, las estimaciones de \(\beta_0,\beta_1,\ldots,\beta_p\) se obtienen minimizando
La regresión ridge es muy similar al enfoque de mínimos cuadrados, pero los coeficientes de la regresión ridge \(\hat{\beta}^R\) son los valores que minimizan
donde \(\lambda\) es un parámetro ajustable que se determina de manera separada. La influencia de la regularización se controla con \(\lambda\). Valores altos de \(\lambda\) significa más regularización y modelos más simples. Sin embargo, la regresión ridge siempre generará un modelo que incluya todos los predictores. Incrementar el valor de \(\lambda\) tenderá a reducir las magnitudes de los coeficientes, pero no resultará en la exclusión de ninguna de las variables. Notemos que la penalidad no se aplica a \(\beta_0\).
10.2.4. Regresión Lasso#
La penalización \(L_1\) tiene el efecto de forzar algunas de las estimaciones de coeficientes a ser exactamente iguales a cero cuando el parámetro \(\lambda\) de ajuste es suficientemente grande. Por lo tanto, lasso realiza selección de variables. Como resultado, los modelos generados a partir de lasso son generalmente mucho más fáciles de interpretar que los producidos por regresión ridge. Decimos que lasso produce modelos dispersos (sparse), es decir, modelos que involucran solo un subconjunto de variables predictoras.
10.2.4.1. Ejemplo#
Volvamos al ejemplo de la superintendencia de compañias del Ecuador
# Importación de bibliotecas necesarias
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge, Lasso, LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
# -------------------------------------------------------------
# DIVISIÓN DE LOS DATOS EN ENTRENAMIENTO Y PRUEBA
# -------------------------------------------------------------
# Divide el conjunto de datos en entrenamiento (80%) y prueba (20%)
# El parámetro random_state garantiza reproducibilidad
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=85)
# -------------------------------------------------------------
# ESCALAMIENTO DE VARIABLES
# -------------------------------------------------------------
# Crea un objeto StandardScaler para estandarizar las variables (media 0, varianza 1)
scaler = StandardScaler()
# Ajusta y transforma los datos de entrenamiento
X_train_scaled = scaler.fit_transform(X_train)
# Transforma los datos de prueba con la misma escala (sin volver a ajustar)
X_test_scaled = scaler.transform(X_test)
# -------------------------------------------------------------
# CREACIÓN Y ENTRENAMIENTO DE MODELOS
# -------------------------------------------------------------
# Define el modelo Ridge con penalización L2 (alpha = 1.0)
ridge = Ridge(alpha=1.0)
# Define el modelo Lasso con penalización L1 (alpha = 5.0)
lasso = Lasso(alpha=5.0)
# Define la regresión lineal sin penalización (modelo base OLS)
regOLS = LinearRegression()
# Ajusta los modelos con los datos de entrenamiento escalados
ridge.fit(X_train_scaled, y_train)
lasso.fit(X_train_scaled, y_train)
regOLS.fit(X_train_scaled, y_train)
# -------------------------------------------------------------
# PREDICCIONES Y EVALUACIÓN EN TRAINING SET
# -------------------------------------------------------------
# Realiza predicciones sobre el conjunto de entrenamiento
y_pred_ridge_tr = ridge.predict(X_train_scaled)
y_pred_lasso_tr = lasso.predict(X_train_scaled)
y_pred_ols_tr = regOLS.predict(X_train_scaled)
# Calcula el error cuadrático medio (MSE) sobre el set de entrenamiento
# num_factor se puede usar si se quiere normalizar el error (aquí vale 1)
num_factor = 1
mse_ridge_tr = mean_squared_error(y_train, y_pred_ridge_tr)/num_factor
mse_lasso_tr = mean_squared_error(y_train, y_pred_lasso_tr)/num_factor
mse_ols_tr = mean_squared_error(y_train, y_pred_ols_tr)/num_factor
# Imprime los resultados de entrenamiento
print("Evaluación del modelo en TRAIN:\n")
print(f"MSE Ridge: {mse_ridge_tr:.2f}")
print(f"MSE Lasso: {mse_lasso_tr:.2f}")
print(f"MSE OLS: {mse_ols_tr:.2f}")
# -------------------------------------------------------------
# PREDICCIONES Y EVALUACIÓN EN TEST SET
# -------------------------------------------------------------
# Realiza predicciones sobre el conjunto de prueba
y_pred_ridge = ridge.predict(X_test_scaled)
y_pred_lasso = lasso.predict(X_test_scaled)
y_pred_ols = regOLS.predict(X_test_scaled)
# Calcula el MSE sobre el set de prueba
mse_ridge = mean_squared_error(y_test, y_pred_ridge)/num_factor
mse_lasso = mean_squared_error(y_test, y_pred_lasso)/num_factor
mse_ols = mean_squared_error(y_test, y_pred_ols)/num_factor
# Imprime los resultados del test
print("\nEvaluación del modelo en TEST:\n")
print(f"MSE Ridge: {mse_ridge:.2f}")
print(f"MSE Lasso: {mse_lasso:.2f}")
print(f"MSE OLS: {mse_ols:.2f}")
Evaluación del modelo en TRAIN:
MSE Ridge: 1852.46
MSE Lasso: 2083.61
MSE OLS: 1852.46
Evaluación del modelo en TEST:
MSE Ridge: 3527.83
MSE Lasso: 3663.03
MSE OLS: 3527.39
# Mostrar coeficientes con nombres
ridge_coefficients = pd.DataFrame(ridge.coef_, index=X.columns, columns=['Ridge Coefficients'])
lasso_coefficients = pd.DataFrame(lasso.coef_, index=X.columns, columns=['Lasso Coefficients'])
ols_coefficients = pd.DataFrame(regOLS.coef_, index=X.columns, columns=['OLS Coefficients'])
# Combinar coeficientes en un solo DataFrame
coefficients = pd.concat([ridge_coefficients, lasso_coefficients,ols_coefficients], axis=1)
print("\nCoeficientes:")
print(coefficients)
Coeficientes:
Ridge Coefficients Lasso Coefficients \
activos 46.452401 51.339290
utilidad_an_imp 7.140067 2.802706
n_empleados 20.230335 15.067053
liquidez_corriente 1.097188 -0.000000
end_activo -0.310678 0.000000
end_patrimonial -2.044002 0.000000
end_activo_fijo -0.244253 -0.000000
end_corto_plazo 3.527861 0.000000
cobertura_interes 0.281633 -0.000000
apalancamiento_financiero -0.502044 -0.000000
end_patrimonial_ct 0.527377 0.000000
end_patrimonial_nct 1.076781 0.000000
rot_cartera 0.157103 0.000000
rot_ventas 1.052480 0.000000
per_med_cobranza -0.919068 -0.000000
per_med_pago 1.745660 0.000000
impac_gasto_a_v -2.108877 -0.000000
impac_carga_finan -4.171406 -0.037732
rent_neta_activo 2.607665 0.000000
margen_bruto -8.536271 -4.644804
margen_operacional 5.138157 0.000000
rent_neta_ventas -4.865955 -0.924355
rent_ope_patrimonio -0.019458 -0.000000
roe 2.066205 0.000000
fortaleza_patrimonial -0.921451 -0.000000
gastos_financieros 3.886436 0.000000
gastos_admin_ventas 31.292825 23.488379
depreciaciones -3.459897 -0.000000
amortizaciones -6.807988 -0.000000
deuda_total 17.489693 14.618748
deuda_total_c_plazo 11.799476 10.246291
OLS Coefficients
activos 46.520173
utilidad_an_imp 7.103579
n_empleados 20.224461
liquidez_corriente 1.098485
end_activo -0.310745
end_patrimonial -2.056202
end_activo_fijo -0.244556
end_corto_plazo 3.530621
cobertura_interes 0.281992
apalancamiento_financiero -0.502272
end_patrimonial_ct 0.530975
end_patrimonial_nct 1.078609
rot_cartera 0.157290
rot_ventas 1.052782
per_med_cobranza -0.924138
per_med_pago 1.746044
impac_gasto_a_v -2.110272
impac_carga_finan -4.169610
rent_neta_activo 2.610887
margen_bruto -8.539168
margen_operacional 5.150837
rent_neta_ventas -4.872438
rent_ope_patrimonio -0.020343
roe 2.076751
fortaleza_patrimonial -0.920677
gastos_financieros 3.868392
gastos_admin_ventas 31.299005
depreciaciones -3.459313
amortizaciones -6.817272
deuda_total 17.486285
deuda_total_c_plazo 11.794246
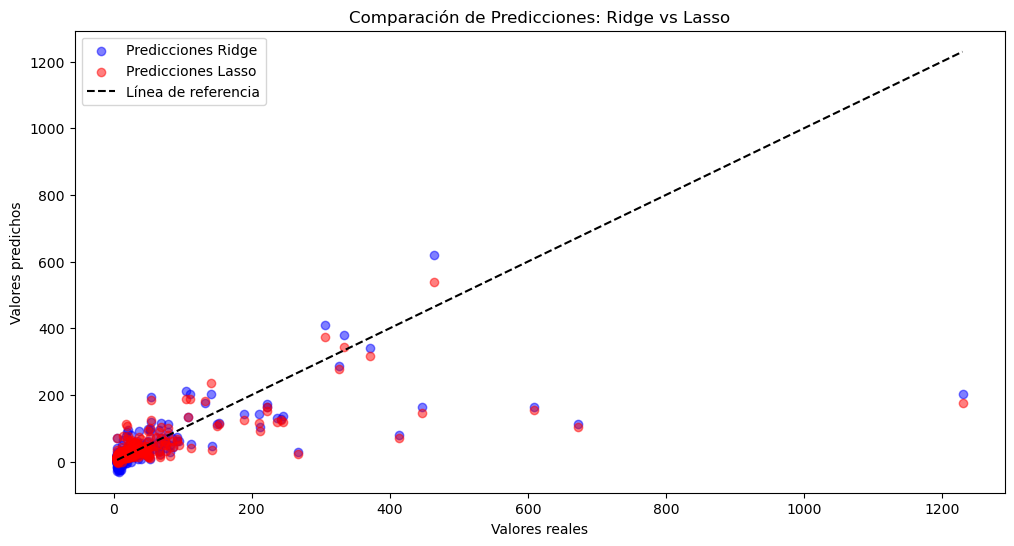
# Graficar los resultados
plt.figure(figsize=(12, 6))
plt.scatter(y_test, y_pred_ridge, color='blue', label="Predicciones Ridge", alpha=0.5)
plt.scatter(y_test, y_pred_lasso, color='red', label="Predicciones Lasso", alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='black', linestyle='--', label="Línea de referencia")
plt.xlabel("Valores reales")
plt.ylabel("Valores predichos")
plt.title("Comparación de Predicciones: Ridge vs Lasso")
plt.legend()
plt.show()
Ajuste con el mejor \(\lambda\)
# Importación de herramientas para validación cruzada y búsqueda de hiperparámetros
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold
# -------------------------------------------------------------
# DEFINICIÓN DEL RANGO DE ALPHA (λ) A PROBAR
# -------------------------------------------------------------
# Define una grilla de valores posibles para el hiperparámetro alpha (lambda)
# Alpha controla la intensidad de la penalización (regularización)
param_grid = {'alpha': [0.1, 0.5, 0.9, 1, 2, 3, 4, 5, 10, 20, 30, 40, 50, 100, 150, 200, 300, 400, 500]}
# -------------------------------------------------------------
# CREACIÓN DE LOS MODELOS BASE
# -------------------------------------------------------------
# Crea instancias de los modelos Ridge y Lasso (aún sin alpha especificado)
ridge = Ridge()
lasso = Lasso()
# -------------------------------------------------------------
# CONFIGURACIÓN DE LA VALIDACIÓN CRUZADA
# -------------------------------------------------------------
# Crea un objeto KFold con 5 particiones (folds), barajando los datos y fijando semilla para reproducibilidad
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
# -------------------------------------------------------------
# BÚSQUEDA DE HIPERPARÁMETROS CON GRIDSEARCHCV
# -------------------------------------------------------------
# Aplica GridSearchCV al modelo Ridge:
# - Se evalúa cada valor de alpha usando validación cruzada con el criterio de error cuadrático medio negativo
# (porque sklearn maximiza por defecto, y el MSE debe minimizarse)
ridge_search = GridSearchCV(
ridge, param_grid, scoring='neg_mean_squared_error', cv=kfold
)
ridge_search.fit(X_train_scaled, y_train) # Entrena sobre los datos de entrenamiento escalados
# Aplica el mismo procedimiento para el modelo Lasso
lasso_search = GridSearchCV(
lasso, param_grid, scoring='neg_mean_squared_error', cv=kfold
)
lasso_search.fit(X_train_scaled, y_train)
# -------------------------------------------------------------
# RESULTADOS ÓPTIMOS DE RIDGE
# -------------------------------------------------------------
# Extrae el mejor valor de alpha para Ridge que minimiza el MSE
best_ridge_alpha = ridge_search.best_params_['alpha']
# Obtiene el mejor score (negativo), y lo multiplica por -1 para obtener el MSE real
best_ridge_mse = -ridge_search.best_score_ / num_factor
# -------------------------------------------------------------
# RESULTADOS ÓPTIMOS DE LASSO
# -------------------------------------------------------------
# Extrae el mejor valor de alpha para Lasso
best_lasso_alpha = lasso_search.best_params_['alpha']
# MSE asociado al mejor alpha encontrado para Lasso (también se vuelve positivo)
best_lasso_mse = -lasso_search.best_score_ / num_factor
# Importación de bibliotecas para visualización y operaciones numéricas
import matplotlib.pyplot as plt
import numpy as np
# -------------------------------------------------------------
# EXTRACCIÓN DE RESULTADOS DEL GRIDSEARCH
# -------------------------------------------------------------
# Accede a los resultados de validación cruzada del GridSearch para Ridge
ridge_results = ridge_search.cv_results_
# Accede a los resultados de validación cruzada del GridSearch para Lasso
lasso_results = lasso_search.cv_results_
# Extrae los valores de alpha evaluados
alphas = ridge_results['param_alpha'].data # Asegura que esté en formato iterable limpio
# -------------------------------------------------------------
# CÁLCULO DE MSE (recordando que estaban como negativos)
# -------------------------------------------------------------
# Convierte los scores negativos de Ridge a MSE positivos
ridge_mse = -ridge_results['mean_test_score']
# Convierte los scores negativos de Lasso a MSE positivos
lasso_mse = -lasso_results['mean_test_score']
# -------------------------------------------------------------
# VISUALIZACIÓN DE LOS RESULTADOS
# -------------------------------------------------------------
# Crea una figura de tamaño amplio
plt.figure(figsize=(14, 7))
# ----------- SUBPLOT PARA RIDGE -----------
plt.subplot(1, 2, 1) # Primer gráfico (1 fila, 2 columnas, posición 1)
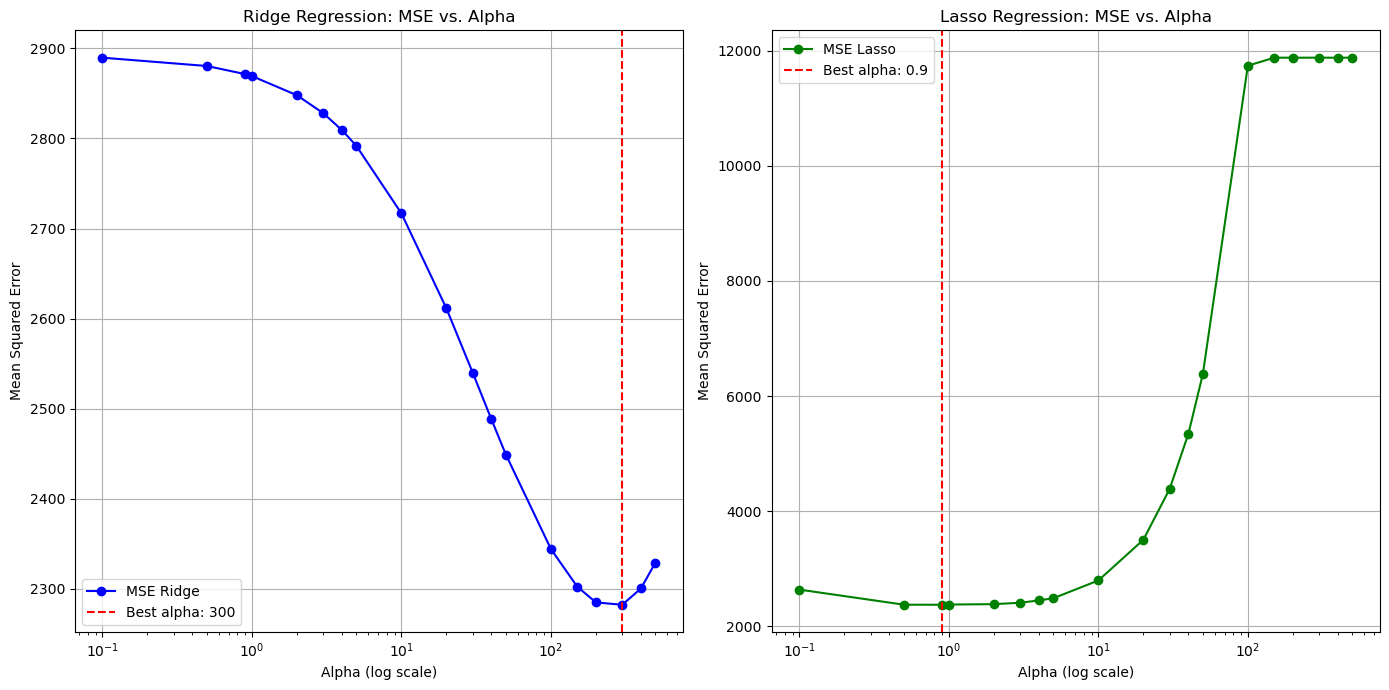
plt.plot(alphas, ridge_mse, marker='o', label='MSE Ridge', color='blue') # Curva MSE vs alpha
plt.axvline(x=best_ridge_alpha, color='red', linestyle='--', label=f'Best alpha: {best_ridge_alpha}') # Línea en el mejor alpha
plt.xscale('log') # Usa escala logarítmica en el eje x
plt.title('Ridge Regression: MSE vs. Alpha')
plt.xlabel('Alpha (log scale)')
plt.ylabel('Mean Squared Error')
plt.legend()
plt.grid(True)
# ----------- SUBPLOT PARA LASSO -----------
plt.subplot(1, 2, 2) # Segundo gráfico (1 fila, 2 columnas, posición 2)
plt.plot(alphas, lasso_mse, marker='o', label='MSE Lasso', color='green') # Curva MSE vs alpha
plt.axvline(x=best_lasso_alpha, color='red', linestyle='--', label=f'Best alpha: {best_lasso_alpha}') # Línea en el mejor alpha
plt.xscale('log') # Escala logarítmica para visualizar bien los valores pequeños
plt.title('Lasso Regression: MSE vs. Alpha')
plt.xlabel('Alpha (log scale)')
plt.ylabel('Mean Squared Error')
plt.legend()
plt.grid(True)
# Ajusta automáticamente el diseño para que no se sobrepongan los elementos
plt.tight_layout()
# Muestra el gráfico final con ambos subplots
plt.show()
# -------------------------------------------------------------
# IMPRESIÓN DE LOS MEJORES RESULTADOS DE VALIDACIÓN CRUZADA
# -------------------------------------------------------------
# Imprime los mejores valores encontrados en la validación cruzada para ambos modelos
print("\nEvaluación del modelo en CV:\n")
print(f"Mejor alpha para Ridge: {best_ridge_alpha}")
print(f"Mejor MSE para Ridge: {best_ridge_mse:.2f} ")
print(f"Mejor alpha para Lasso: {best_lasso_alpha}")
print(f"Mejor MSE para Lasso: {best_lasso_mse:.2f} ")
# -------------------------------------------------------------
# AJUSTAR LOS MODELOS CON LOS MEJORES ALPHA
# -------------------------------------------------------------
# Crea nuevas instancias de Ridge y Lasso con los mejores valores de alpha
ridge_best = Ridge(alpha=best_ridge_alpha)
lasso_best = Lasso(alpha=best_lasso_alpha)
# Ajusta ambos modelos con los datos de entrenamiento escalados
ridge_best.fit(X_train_scaled, y_train)
lasso_best.fit(X_train_scaled, y_train)
# -------------------------------------------------------------
# PREDICCIONES Y MSE EN TRAINING SET
# -------------------------------------------------------------
# Realiza predicciones sobre el conjunto de entrenamiento usando los modelos ajustados con el mejor alpha
y_pred_ridge_best_tr = ridge_best.predict(X_train_scaled)
y_pred_lasso_best_tr = lasso_best.predict(X_train_scaled)
# Calcula el MSE en el conjunto de entrenamiento
mse_ridge_best_tr = mean_squared_error(y_train, y_pred_ridge_best_tr) / num_factor
mse_lasso_best_tr = mean_squared_error(y_train, y_pred_lasso_best_tr) / num_factor
# Imprime los MSE obtenidos en entrenamiento
print("\nEvaluación del modelo en TRAIN:\n")
print(f"\nMSE Ridge con mejor alpha: {mse_ridge_best_tr:.2f}")
print(f"MSE Lasso con mejor alpha: {mse_lasso_best_tr:.2f} ")
# -------------------------------------------------------------
# PREDICCIONES Y MSE EN TEST SET
# -------------------------------------------------------------
# Realiza predicciones sobre el conjunto de prueba usando los modelos ajustados con el mejor alpha
y_pred_ridge_best = ridge_best.predict(X_test_scaled)
y_pred_lasso_best = lasso_best.predict(X_test_scaled)
# Calcula el MSE en el conjunto de prueba
mse_ridge_best = mean_squared_error(y_test, y_pred_ridge_best) / num_factor
mse_lasso_best = mean_squared_error(y_test, y_pred_lasso_best) / num_factor
# Imprime los MSE obtenidos en prueba (test)
print("\nEvaluación del modelo en TEST:\n")
print(f"\nMSE Ridge con mejor alpha: {mse_ridge_best:.2f}")
print(f"MSE Lasso con mejor alpha: {mse_lasso_best:.2f} ")
Evaluación del modelo en CV:
Mejor alpha para Ridge: 300
Mejor MSE para Ridge: 2282.32
Mejor alpha para Lasso: 0.9
Mejor MSE para Lasso: 2374.17
Evaluación del modelo en TRAIN:
MSE Ridge con mejor alpha: 1903.47
MSE Lasso con mejor alpha: 1871.67
Evaluación del modelo en TEST:
MSE Ridge con mejor alpha: 3617.36
MSE Lasso con mejor alpha: 3534.08