17. Minería de Reglas de asociación#
(Association Rule Mining)
La minería de reglas de asociación se usa cuando desea encontrar una asociación entre diferentes objetos en un conjunto, buscar patrones frecuentes en una base de datos de transacciones, bases de datos relacionales o cualquier otro repositorio de información.
Las aplicaciones de ARM se encuentran en Marketing, Análisis de datos de cesta (o Análisis de cesta de mercado) en venta minorista, agrupación y clasificación. Puede decirle qué artículos compran juntos con frecuencia los clientes al generar un conjunto de reglas llamadas Reglas de asociación. En palabras simples, le da salida como reglas en forma si esto, entonces eso. Los clientes pueden usar esas reglas para numerosas estrategias de marketing:
Cambiar el diseño de la tienda según las tendencias.
Análisis del comportamiento del cliente.
Diseño del catálogo.
Marketing cruzado en tiendas en línea.
¿Cuáles son los artículos de tendencia que los clientes compran?
Correos electrónicos personalizados con ventas adicionales.
Considere el siguiente ejemplo:

Se tiene un conjunto de datos de transacciones. Puede ver las transacciones numeradas del 1 al 5. Cada transacción muestra los artículos comprados en esa transacción. Puede ver que el pañal se compra con cerveza en tres transacciones. Del mismo modo, el pan se compra con leche en tres transacciones, lo que los convierte en conjuntos de artículos frecuentes. Las reglas de asociación se dan de la siguiente manera:
También se lee como Antecedente \(\Rightarrow\) Consecuente.
\(A\) y \(B\) son conjuntos de ítems en los datos transaccionales y son disjuntos. Ejemplo:
que se lee como:
\(20\%\) de transacciones muestran que el antivirus se compra con la compra de una computadora.
El \(60\%\) del total del ventas de computadora, también compra antivirus.
Veamos algunos conceptos básicos
Itemset: Colección de uno o más ítems. Un conjunto \(k-item\) contiene \(k\) items.
Conteo de soporte: frecuencia de ocurrencia de un conjunto de ítems.
Soporte (\(s\)): Porcentaje de transacciones que contienen el conjunto de ítems \(X\).
Para la regla \(A \Rightarrow B\), el Soporte está dado por:
Nota: \(P(A\cup B)\) es la probabilidad conjunta de \(A\) y \(B\).
Ejercicio Encuentra el soporte de \(Leche \Rightarrow Pañal\)
Confianza (\(c\)): En la regla \(A \Rightarrow B\) la confianza muestra el porcentaje en la que \(A\) y \(B\) se compran juntos respecto al número total de transacciones que contienen \(A\).
Ejemplo:
Ejercicio Encuentra la confianza de \(Leche \Rightarrow Pañal\)
Nota: El analista debe establecer el soporte y confianza mínimos que desea.
Itemsets frecuentes: Los conjuntos de items cuyo soporte es mayor o igual al soporte mínimo (min_sup).
Reglas fuertes: Si la regla \(A \Rightarrow B [Soporte, Confianza]\) cumple con \(min_{sup}\) y \(min_{confianza}\) entonces es una regla fuerte.
Lift: es la correlación entre \(A\) y \(B\) en la regla \(A \Rightarrow B\)
Ejemplo: \(Pan \Rightarrow Leche\)
Si el Lift es 1, entonces A y B son independientes y no se puede extraer una regla.
Si el Lift es > 1, entonces A y B son dependientes y el grado de dependencia se da por el valor.
Si el Lift es < 1, entonces A tiene un efecto negativo en B.
Coverage: es el soporte de la parte izquierda de la regla (antecedente). Se interpreta como la frecuencia con la que el antecedente aparece en el conjunto de transacciones.
17.1. Algoritmo apriori#
Generación del conjunto de ítems frecuente: Encontrar todos los conjuntos de ítems cuyo soporte sea >= al min_sup
Generación de la regla: Listar todas las reglas de asociación de los conjuntos de ítems frecuentes. Calcular el soporte y la confianza de todas las reglas. Podar las reglas que no cumplen con min_sup ni min_confianza
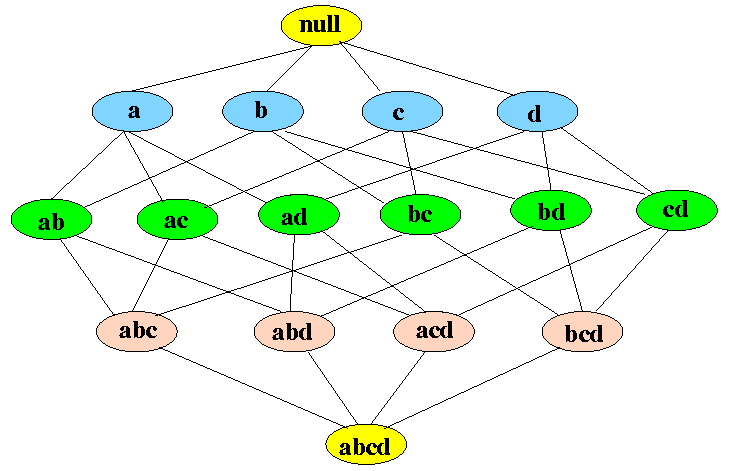
Apriori es un algoritmo de minería de datos usado para extraer conjuntos de ítems frecuentes y generar reglas de asociación. Se basa en la idea de que:
“Si un conjunto es frecuente, todos sus subconjuntos también lo son.”
Pasos del algoritmo Apriori
Generación del conjunto de ítems frecuentes
“Encontrar todos los conjuntos de ítems cuyo soporte sea ≥ al
min_sup”
Se parte del conjunto vacío (
null) y se generan ítems individuales:a,b,c,d(nivel 1).Luego, se combinan en pares:
ab,ac,ad,bc,bd,cd(nivel 2).Luego en tríos:
abc,abd,acd,bcd(nivel 3).Finalmente, un conjunto con 4 ítems:
abcd(nivel 4).
Los nodos coloreados indican si el conjunto cumple con el mínimo soporte (min_sup):
🟡 Amarillo: conjunto inicial (
null) o conjuntos demasiado grandes.🔵 Azul: ítems individuales.
🟢 Verde: conjuntos que cumplen con
min_sup.🟤 Rosado: conjuntos que no cumplen con
min_supy son podados.
Este proceso se llama “nivel por nivel” o “bottom-up”, y en cada paso se eliminan los conjuntos no frecuentes (esto ahorra tiempo y memoria).
Generación de reglas de asociación
“Listar todas las reglas de asociación de los conjuntos de ítems frecuentes. Calcular el soporte y la confianza de todas las reglas. Podar las reglas que no cumplan con
min_supnimin_confianza”
Una vez que se identifican los conjuntos frecuentes (como ab, abc, bd, etc.), se generan reglas como:
{a} → {b}{a, b} → {c}{b} → {d}
Cada regla se evalúa usando:
Soporte: frecuencia con la que aparece el conjunto completo (antecedente + consecuente).
Confianza: probabilidad de que ocurra el consecuente dado el antecedente.
Se eliminan (se podan) las reglas que no cumplen con los umbrales min_sup y min_confianza.
¿Qué representa cada nivel del grafo?
Nivel 0: Conjunto vacío (
null)Nivel 1: Ítems individuales
{a},{b},{c},{d}Nivel 2: Combinaciones de 2 ítems
{ab},{ac},{bd}, etc.Nivel 3: Combinaciones de 3 ítems
{abc},{abd}, etc.Nivel 4: Conjunto completo
{abcd}
Las flechas indican las relaciones de inclusión: cada conjunto en un nivel superior se construye a partir de los ítems en los niveles inferiores.
¿Por qué se llama Apriori?
Porque se basa en el principio a priori de que “los superset de un conjunto infrecuente también serán infrecuentes”. Es decir, si {ab} no es frecuente, entonces {abc}, {abd}, {abcd} tampoco lo serán. Esto permite podar el espacio de búsqueda eficientemente.
17.1.1. Ejemplo en Python#
import numpy as np
import pandas as pd
# Productos simulados
products = ['milk', 'bread', 'butter', 'apples', 'bananas', 'eggs', 'cheese', 'yogurt']
# Crear 1000 transacciones aleatorias con presencia (1) o ausencia (0) de cada producto
np.random.seed(42)
n_transactions = 1000
groceries_data = pd.DataFrame(np.random.randint(2, size=(n_transactions, len(products))), columns=products)
groceries_data.head()
| milk | bread | butter | apples | bananas | eggs | cheese | yogurt | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| 4 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
from mlxtend.frequent_patterns import apriori, association_rules # Para minería de reglas de asociación
import matplotlib.pyplot as plt # Para gráficos (equivalente a ggplot2)
import seaborn as sns # Para visualización de datos
from datetime import datetime # Equivalente a lubridate
Parámetros de apriori
mlxtend.frequent_patterns.apriori(
df,
min_support=0.5,
use_colnames=False,
max_len=None,
verbose=0,
low_memory=False,
filter_col=None,
filter_value=True
)
Parámetro |
Tipo |
Descripción |
|---|---|---|
|
DataFrame |
Matriz one-hot encoded: filas = transacciones, columnas = ítems (0 o 1). |
|
float |
Soporte mínimo requerido (entre 0 y 1). |
|
bool |
Si |
|
int o None |
Longitud máxima de los itemsets considerados. |
|
int |
Nivel de verbosidad (0 por defecto). |
|
bool |
Si |
|
str |
Nombre de columna booleana para filtrar transacciones. |
|
bool |
Valor que debe tener |
Salida esperada
El resultado es un DataFrame con los siguientes campos:
Columna |
Tipo |
Descripción |
|---|---|---|
|
float |
Proporción de transacciones que contienen el itemset. |
|
frozenset |
Conjunto de ítems frecuentes encontrados. |
Puedes agregar una columna con la longitud del itemset si lo deseas:
frequent_itemsets['length'] = frequent_itemsets['itemsets'].apply(len)
Parámetros de association_rules
mlxtend.frequent_patterns.association_rules(
frequent_itemsets,
metric='confidence',
min_threshold=0.8
)
Parámetro |
Tipo |
Descripción |
|---|---|---|
|
DataFrame |
Resultado del método |
|
str |
Métrica para evaluar la calidad de la regla. Opciones: |
|
float |
Umbral mínimo requerido para la métrica especificada. |
Salida esperada
Un DataFrame con las siguientes columnas:
Columna |
Descripción |
|---|---|
|
Itemset del lado izquierdo de la regla. |
|
Itemset del lado derecho de la regla. |
|
Soporte del antecedente. |
|
Soporte del consecuente. |
|
Soporte conjunto (antecedente + consecuente). |
|
Proporción de veces que la regla es verdadera. |
|
Medida del aumento en probabilidad respecto a independencia. |
|
Diferencia entre soporte observado y esperado si fueran independientes. |
|
Medida de certeza de implicación. |
# Suponiendo que 'groceries_data' es un DataFrame con transacciones binarias (uno para presencia del producto, cero para ausencia)
groceries_data = groceries_data.astype(bool)
# Aplicar el algoritmo Apriori
frequent_itemsets = apriori(groceries_data, min_support=0.001, use_colnames=True)
# Generar las reglas de asociación
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.8)
# Mostrar las 10 reglas con el mayor 'lift'
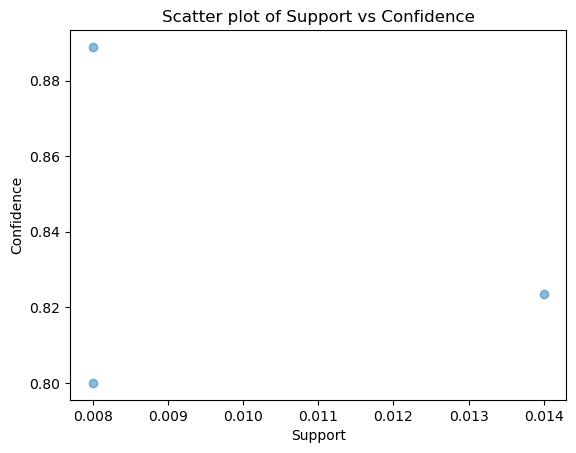
rules.sort_values('lift', ascending=False).head(10)
| antecedents | consequents | antecedent support | consequent support | support | confidence | lift | representativity | leverage | conviction | zhangs_metric | jaccard | certainty | kulczynski | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | (apples, yogurt, milk, cheese, eggs, butter, b... | (bananas) | 0.009 | 0.510 | 0.008 | 0.888889 | 1.742919 | 1.0 | 0.003410 | 4.410000 | 0.430121 | 0.015656 | 0.773243 | 0.452288 |
| 0 | (apples, bananas, yogurt, cheese, eggs, butter) | (bread) | 0.017 | 0.501 | 0.014 | 0.823529 | 1.643771 | 1.0 | 0.005483 | 2.827667 | 0.398416 | 0.027778 | 0.646352 | 0.425737 |
| 1 | (apples, bananas, yogurt, milk, cheese, butter... | (eggs) | 0.010 | 0.494 | 0.008 | 0.800000 | 1.619433 | 1.0 | 0.003060 | 2.530000 | 0.386364 | 0.016129 | 0.604743 | 0.408097 |
# Visualización de las reglas (por ejemplo, usando un gráfico de dispersión)
import seaborn as sns
import matplotlib.pyplot as plt
plt.scatter(rules['support'], rules['confidence'], alpha=0.5)
plt.xlabel('Support')
plt.ylabel('Confidence')
plt.title('Scatter plot of Support vs Confidence')
plt.show()